AI风控之伪造视频检测
安全工具
Deepfake技术是一种利用人工智能深度学习算法生成虚假内容的手段。通过训练模型识别和模仿特定人物的面部特征、声音甚至行为方式,Deepfake可以合成出极为逼真的虚假视频或音频。这种技术的关键在于其高度的欺骗性,使得辨别真伪变得异常困难。
前言 == Deepfake技术是一种利用人工智能深度学习算法生成虚假内容的手段。通过训练模型识别和模仿特定人物的面部特征、声音甚至行为方式,Deepfake可以合成出极为逼真的虚假视频或音频。这种技术的关键在于其高度的欺骗性,使得辨别真伪变得异常困难。 Deepfake伪造视频对社会的影响是多方面的。它严重侵犯了个人隐私权,通过伪造他人形象进行不实传播,给被伪造者带来名誉损害和精神压力。Deepfake在政治领域的影响尤为显著,它可以被用来制造假新闻,篡改公众对事件的看法,甚至影响选举结果。此外,Deepfake还可能被用于商业欺诈,通过伪造高管访谈等手段误导投资者,造成经济损失。  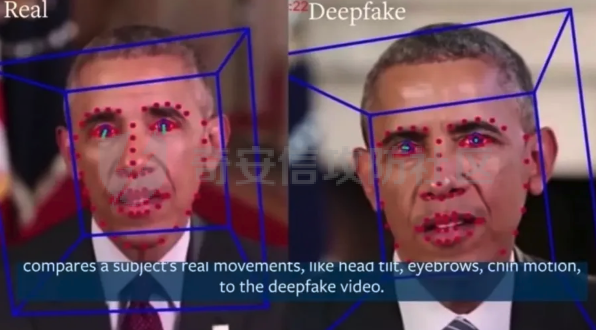 因此在风控等场合下如何有效对deepfake伪造视频进行有效鉴伪就是急需解决的事情。本文就来分享一个简单有效的方案。 背景知识 ==== 在实战之前,我们先来补一下背景知识 deepfake -------- Deepfake技术的核心原理是利用生成对抗网络(GAN)或卷积神经网络(CNN)等算法将目标对象的面部“嫁接”到被模仿对象上。由于视频是连续的图片组成,因此只需要把每一张图片中的脸替换,就能得到变脸的新视频。具体而言,首先将模仿对象的视频逐帧转化成大量图片,然后将目标模仿对象面部替换成目标对象面部。最后,将替换完成的图片重新合成为假视频,而深度学习技术可以使这一过程实现自动化。 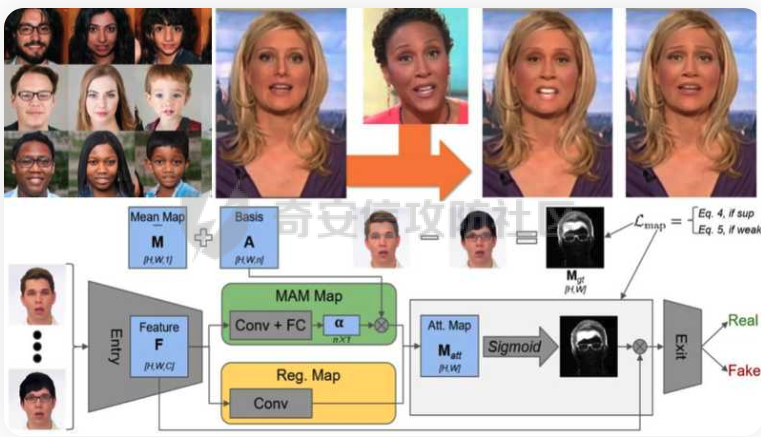 脸部交换是一种常见的类型。最流行的包含假视频和真实视频的数据库是FaceForensics++。该数据集中的假视频是使用计算机图形学(FaceSwap)和深度学习方法(DeepFake FaceSwap)制作的。FaceSwap应用程序是用Python编写的,它使用面部对齐、高斯-牛顿优化和图像混合技术,将摄像头看到的人脸与提供图像中的人脸进行交换。DeepFake FaceSwap方法基于两个具有共享编码器的自动编码器,分别训练重建源脸和目标脸的训练图像。目标序列中的人脸被替换为在源视频或图像集中观察到的人脸。使用人脸检测器裁剪并对齐图像。为了创建假图像,应用源脸的训练编码器和解码器到目标脸上。然后,自动编码器的输出与图像的其余部分使用泊松图像编辑进行混合。具体效果如下所示 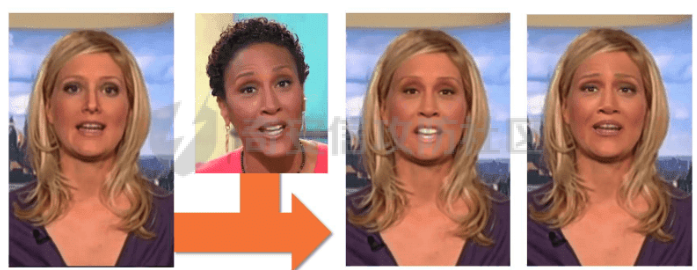 也可以实现表情操纵,包括修改面部的属性,例如头发或皮肤的颜色、年龄、性别,以及使面部表现出高兴、悲伤或愤怒的表情。最流行的例子是最近推出的FaceApp移动应用程序。这些方法大多数采用生成对抗网络(GANs)进行图像到图像的转换。下图就是一个示例  如下就是其中用到的StarGAN的结构 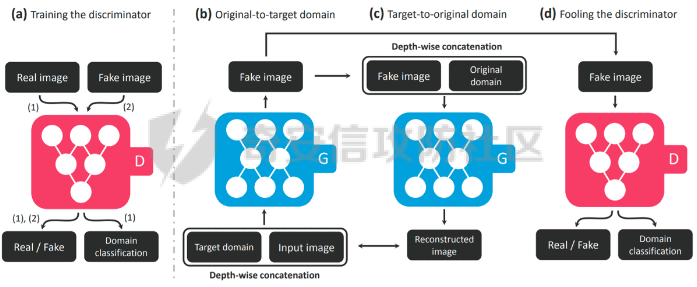 StarGAN由鉴别器D和生成器G组成。鉴别器试图预测输入图像是假的还是真实的,并将真实图像分类到其对应的域。生成器接受图像和目标域标签作为输入,并生成一个假图像。目标域标签在空间上复制并与输入图像连接。然后,生成器试图根据原始域标签从假图像重构出原始图像。最后,生成器G努力生成与真实图像无法区分且能够被鉴别器分类为目标域的图像。 实战 == 数据分析 ---- 首先统计我们目前手头的给定文件夹中的训练样本和测试样本的数量 ```php DATA_FOLDER = 'deepfake' TRAIN_SAMPLE_FOLDER = 'train_sample_videos' TEST_FOLDER = 'test_videos' print(f"Train samples: {len(os.listdir(os.path.join(DATA_FOLDER, TRAIN_SAMPLE_FOLDER)))}") print(f"Test samples: {len(os.listdir(os.path.join(DATA_FOLDER, TEST_FOLDER)))}") ``` 1. `DATA_FOLDER = '../input/deepfake-detection-challenge'`:定义一个变量`DATA_FOLDER`,其值为字符串`'../input/deepfake-detection-challenge'`。这个值表示数据集的根目录。 2. `TRAIN_SAMPLE_FOLDER = 'train_sample_videos'`:定义一个变量`TRAIN_SAMPLE_FOLDER`,其值为字符串`'train_sample_videos'`。这个值表示存储训练样本视频的子目录名称。 3. `TEST_FOLDER = 'test_videos'`:定义一个变量`TEST_FOLDER`,其值为字符串`'test_videos'`。这个值表示存储测试样本视频的子目录名称。 4. `print(f"Train samples: {len(os.listdir(os.path.join(DATA_FOLDER, TRAIN_SAMPLE_FOLDER)))}")`:这行代码首先使用`os.path.join()`函数将`DATA_FOLDER`和`TRAIN_SAMPLE_FOLDER`两个变量的值拼接起来,得到训练样本视频的绝对路径。然后使用`os.listdir()`函数获取该路径下的所有文件和子目录列表。最后,使用`len()`函数计算列表的长度,即训练样本的数量,并通过格式化字符串(f-string)在控制台输出结果。 5. `print(f"Test samples: {len(os.listdir(os.path.join(DATA_FOLDER, TEST_FOLDER)))}")`:这行代码的逻辑与第4行代码类似,只是将`TRAIN_SAMPLE_FOLDER`替换为`TEST_FOLDER`,用于计算并输出测试样本的数量。 执行后如下所示 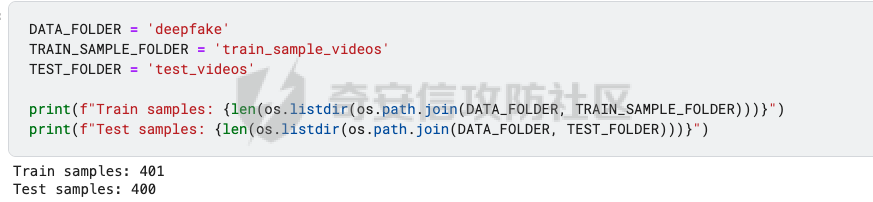 读取训练样本的元数据信息,并将其存储在一个Pandas DataFrame中 ```php train_sample_metadata = pd.read_json('../input/deepfake-detection-challenge/train_sample_videos/metadata.json').T train_sample_metadata.head(): ``` 1. `train_sample_metadata = pd.read_json('../input/deepfake-detection-challenge/train_sample_videos/metadata.json').T`:这行代码使用Pandas库的`read_json()`函数从指定的JSON文件中读取数据。文件路径是`'../input/deepfake-detection-challenge/train_sample_videos/metadata.json'`,这是训练样本视频元数据的存储位置。`.T`操作是对读取到的DataFrame进行转置,使得原本的列名成为索引。 2. `train_sample_metadata.head()`:这行代码调用Pandas DataFrame的`head()`方法,显示DataFrame的前几行(默认为前5行)。这有助于查看元数据的大致结构和内容。 从JSON文件中读取训练样本的元数据信息,并将其存储在一个Pandas DataFrame中。接着,它会显示这个DataFrame的前几行,以便我们查看元数据的结构和内容 ```php train_sample_metadata = pd.read_json('deepfake/train_sample_videos/metadata.json').T train_sample_metadata.head() ``` 执行后如下所示  对训练样本的标签进行分组统计,并绘制一个柱状图来展示训练集中各个标签的分布情况 ```php train_sample_metadata.groupby('label')['label'].count().plot(figsize=(15, 5), kind='bar', title='Distribution of Labels in the Training Set') plt.show() ``` 执行后如下所示 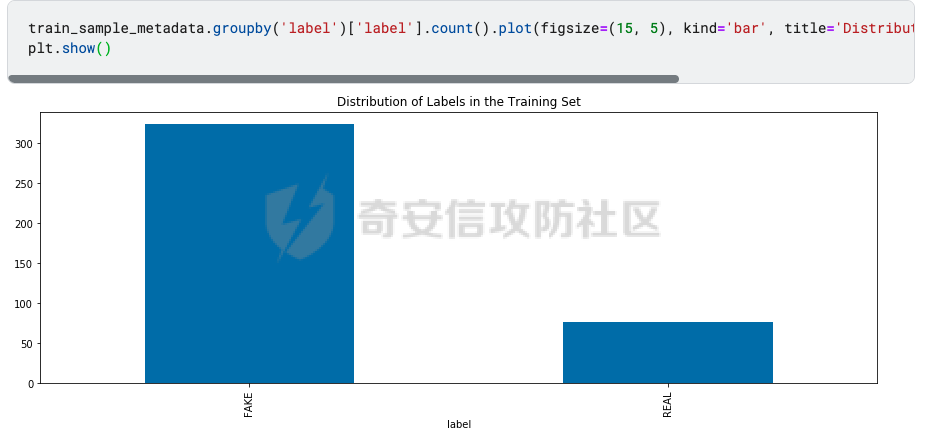 ```php train_sample_metadata.shape ``` `train_sample_metadata.shape` 是一个Pandas DataFrame属性,它返回一个包含两个元素的元组,分别表示DataFrame的行数和列数。在这个例子中,`train_sample_metadata` 是从训练样本的元数据JSON文件中读取的数据。 从训练样本的元数据中随机选取3个标签为'FAKE'的样本,并获取它们的索引(即文件名) ```php fake_train_sample_video = list(train_sample_metadata.loc[train_sample_metadata.label=='FAKE'].sample(3).index) fake_train_sample_video ``` 执行后如下所示 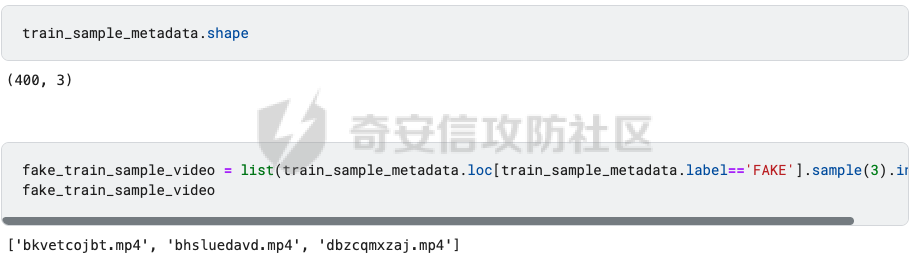 定义一个名为`display_image_from_video`的函数,它接受一个参数`video_path`,表示视频文件的路径。函数的目的是从给定的视频中捕获一帧图像,并在matplotlib图中显示该图像 ```php def display_image_from_video(video_path): capture_image = cv2.VideoCapture(video_path) ret, frame = capture_image.read() fig = plt.figure(figsize=(10,10)) ax = fig.add_subplot(111) frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) ax.imshow(frame) ```  执行后如下所示  以上是伪造的视频,再来看看真实的视频 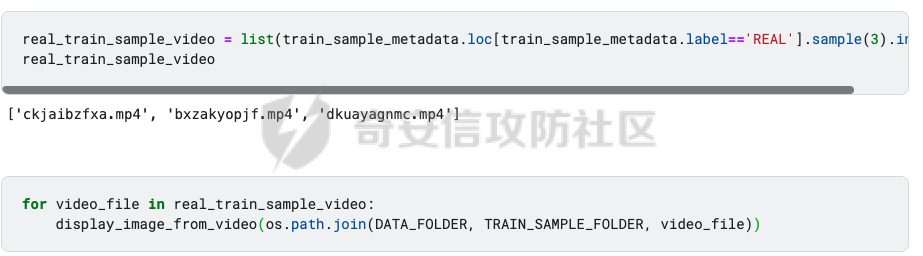 执行后如下所示 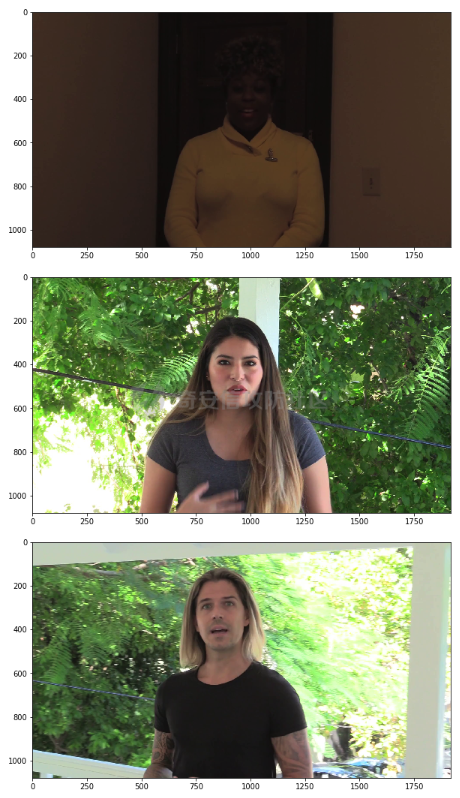 以上就是真实的视频 统计训练样本元数据中'original'列的值的出现次数,并显示出现次数最多的前5个值 ```php train_sample_metadata['original'].value_counts()[0:5] ``` 定义一个名为`display_image_from_video_list`的函数,它接受两个参数:`video_path_list`(一个包含视频文件名的列表)和`video_folder`(视频文件所在的文件夹,默认值为`TRAIN_SAMPLE_FOLDER`)。函数的目的是遍历给定的视频文件名列表,从每个视频中捕获一帧图像,并在matplotlib图中显示这些图像 ```php def display_image_from_video_list(video_path_list, video_folder=TRAIN_SAMPLE_FOLDER): plt.figure() fig, ax = plt.subplots(2,3,figsize=(16,8)) for i, video_file in enumerate(video_path_list[0:6]): video_path = os.path.join(DATA_FOLDER, video_folder,video_file) capture_image = cv2.VideoCapture(video_path) ret, frame = capture_image.read() frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) ax[i//3, i%3].imshow(frame) ax[i//3, i%3].set_title(f"Video: {video_file}") ax[i//3, i%3].axis('on') ``` 首先从训练样本的元数据中筛选出具有相同'original'值(在本例中为'atvmxvwyns.mp4')的所有样本,并将它们的索引(即文件名)存储在`same_original_fake_train_sample_video`列表中。然后,使用之前定义的`display_image_from_video_list`函数显示这些样本的视频帧 ```php same_original_fake_train_sample_video = list(train_sample_metadata.loc[train_sample_metadata.original=='atvmxvwyns.mp4'].index) display_image_from_video_list(same_original_fake_train_sample_video) ``` 运行这段代码后,将看到一个包含6个子图的matplotlib图,每个子图显示一个具有相同'original'值的样本的视频帧。由于`display_image_from_video_list`函数默认只显示前6个视频帧,因此如果筛选出的样本数量超过6个,只有前6个会被显示。 执行后如下所示  从测试集(`TEST_FOLDER`)中选取一个特定的视频文件,然后从这个视频中捕获一帧图像,并在matplotlib图中显示该图像 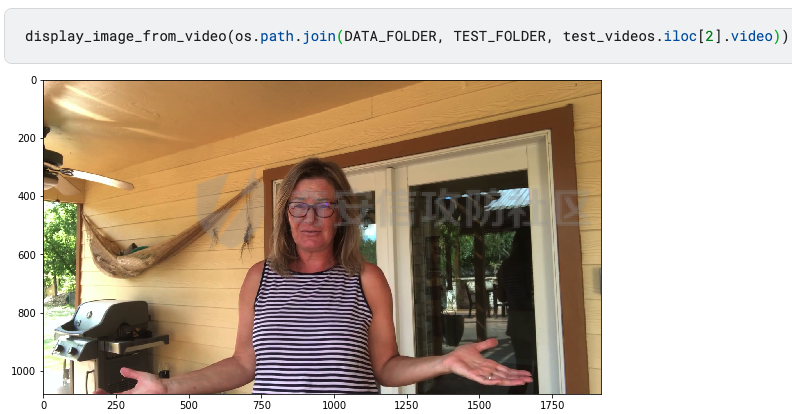 定义了一个名为`play_video`的函数,用于播放指定的视频文件。函数接受两个参数:`video_file`(要播放的视频文件名)和`subset`(视频文件所在的文件夹,默认值为`TRAIN_SAMPLE_FOLDER`) ```php from IPython.display import HTML from base64 import b64encode def play_video(video_file, subset=TRAIN_SAMPLE_FOLDER): video_url = open(os.path.join(DATA_FOLDER, subset,video_file),'rb').read() data_url = "data:video/mp4;base64," + b64encode(video_url).decode() return HTML("""<video width=500 controls><source src="%s" type="video/mp4"></video>""" % data_url) play_video(fake_videos[10]) ``` 执行后如下所示 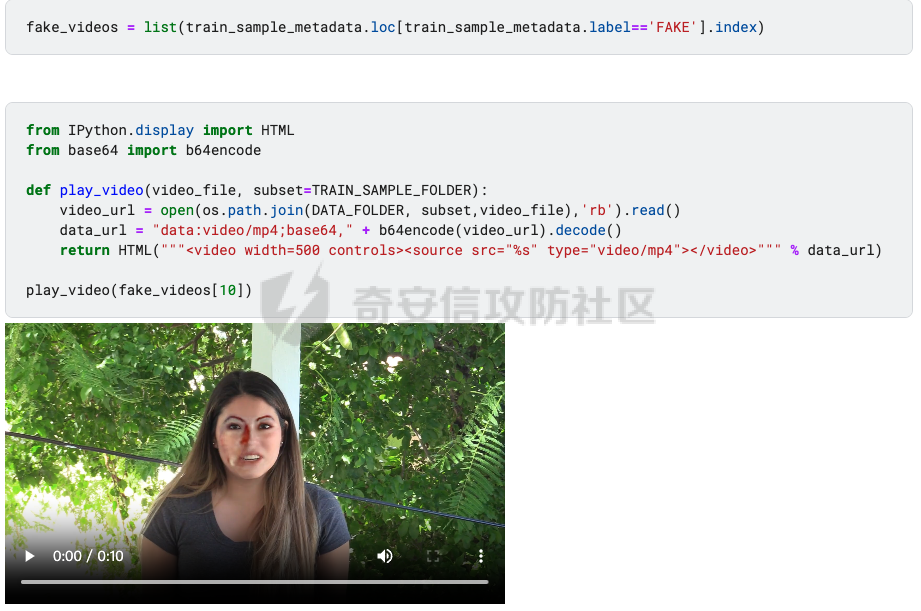 辅助函数 ---- 现在我们尝试使用逻辑回归实现对伪造视频的检测 首先导入相关库文件 ```php import torch import torch.nn as nn import torch.optim as optim import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from tqdm.notebook import tqdm device = 'cuda:0' if torch.cuda.is_available() else 'cpu' print(f'Running on device: {device}') ``` 定义辅助函数,如下代码定义了一个用于逻辑回归的类 ```php class LogisticRegression(nn.Module): def __init__(self, D_in=1, D_out=1): super(LogisticRegression, self).__init__() self.linear = nn.Linear(D_in, D_out) def forward(self, x): y_pred = self.linear(x) return y_pred def predict(self, x): result = self.forward(x) return torch.sigmoid(result) ``` 1. **类定义和继承**: - `LogisticRegression` 类继承自 `nn.Module`,这是 PyTorch 中所有神经网络模块的基类。 2. **初始化方法**: - `__init__` 方法初始化类的实例。它接收两个参数 `D_in` 和 `D_out`,分别表示输入和输出的维度,默认值均为 1。 - 调用父类的初始化方法。 - 创建一个线性层 `linear`,其输入维度为 `D_in`,输出维度为 `D_out`。 3. **前向传播方法**: - `forward` 方法定义了前向传播的计算过程。 - 输入 `x` 通过线性层 `linear` 计算输出 `y_pred`,并返回该输出。 4. **预测方法**: - `predict` 方法用于生成预测结果。 - 输入 `x` 通过前向传播计算线性输出 `result`。 - 对 `result` 应用 Sigmoid 函数,将结果映射到 \[0, 1\] 区间,得到概率输出。 总结起来,这个类定义了一个简单的逻辑回归模型,其中: - 初始化方法创建线性层。 - 前向传播方法计算线性变换的输出。 - 预测方法对输出应用 Sigmoid 函数,生成概率预测。 如下函数的作用是将输入的样本数据和标签数据同时随机打乱,以用于数据集的随机化操作,比如在训练机器学习模型之前进行数据预处理。 ```php def shuffle_data(X, y): assert len(X) == len(y) p = np.random.permutation(len(X)) return X[p], y[p] ``` 1. **函数定义和参数**: - `shuffle_data` 是一个函数,它接收两个参数:`X` 和 `y`。`X` 是样本数据,通常是一个二维数组或矩阵,每一行代表一个样本;`y` 是标签数据,通常是一维数组或列表,每个元素对应 `X` 中的一个样本。 2. **长度检查**: - 函数首先通过 `assert` 语句检查 `X` 和 `y` 的长度是否相等。这是为了确保每个样本都有一个对应的标签。如果长度不一致,会抛出一个断言错误。 3. **生成随机排列**: - 使用 `np.random.permutation(len(X))` 生成一个长度为 `X` 的随机排列数组 `p`。这个数组包含从 0 到 `len(X)-1` 的整数,但顺序是随机的。 4. **应用随机排列**: - 返回 `X[p]` 和 `y[p]`。这里的 `p` 是随机排列的索引数组,通过 `X[p]` 和 `y[p]` 可以将 `X` 和 `y` 按照相同的随机顺序重新排列,保证样本和对应的标签依然匹配。 然后分割训练集和测试集  接着训练分类器 如下代码通过迭代多个 epoch,对逻辑回归模型进行训练和验证。在每个 epoch 中,代码打乱训练数据,分批次进行训练,计算损失,并通过优化器更新模型参数。在每个 epoch 结束后,代码在验证数据上评估模型性能,并根据验证损失保存最佳模型。整个过程通过 `tqdm` 显示训练进度和相关损失信息。 classifier = LogisticRegression() criterion = nn.BCEWithLogitsLoss(reduction='mean', pos\_weight=pos\_weight) # Improve stability optimizer = optim.Adam(classifier.parameters(), lr=LR) n\_batches = np.ceil(len(X\_train) / BATCH\_SIZE).astype(int) losses = np.zeros(EPOCHS) val\_losses = np.zeros(EPOCHS) best\_val\_loss = 1e7 for e in tqdm(range(EPOCHS)): batch\_losses = np.zeros(n\_batches) pbar = tqdm(range(n\_batches)) pbar.desc = f'Epoch {e+1}' classifier.train() ```php X_train, y_train = shuffle_data(X_train, y_train) for i in pbar: X_batch = X_train[i*BATCH_SIZE:min(len(X_train), (i+1)*BATCH_SIZE)] y_batch = y_train[i*BATCH_SIZE:min(len(y_train), (i+1)*BATCH_SIZE)] y_pred = classifier(X_batch) loss = criterion(y_pred, y_batch) batch_losses[i] = loss optimizer.zero_grad() loss.backward() optimizer.step() losses[e] = batch_losses.mean() classifier.eval() y_val_pred = classifier(X_val) val_losses[e] = criterion(y_val_pred, y_val) if val_losses[e] < best_val_loss: print('Found a better checkpoint!') torch.save(classifier.state_dict(), SAVE_PATH) best_val_loss = val_losses[e] pbar.set_postfix({ 'loss': losses[e], 'val_loss': val_losses[e] }) ``` 1. **模型、损失函数和优化器的初始化**: - 创建 `LogisticRegression` 类的实例 `classifier`。 - 定义损失函数 `criterion`,使用 `nn.BCEWithLogitsLoss` 处理二分类任务,并提高稳定性。 - 定义优化器 `optimizer`,使用 Adam 优化算法来更新模型参数。 2. **批次和损失变量的初始化**: - 计算每个 epoch 中的批次数量 `n_batches`。 - 初始化 `losses` 和 `val_losses` 数组用于存储每个 epoch 的训练和验证损失。 - 初始化 `best_val_loss` 用于存储最佳验证损失。 3. **训练循环**: - 使用 `tqdm` 库显示训练进度条。 - 每个 epoch 开始时,将训练数据 `X_train` 和 `y_train` 打乱。 - 进入批次循环,对于每个批次: - 获取当前批次的训练数据和标签。 - 通过模型计算预测值 `y_pred`。 - 计算损失 `loss`。 - 清零优化器的梯度,执行反向传播并更新模型参数。 - 将当前批次的损失存储在 `batch_losses` 中。 - 计算并存储当前 epoch 的平均训练损失。 4. **验证过程**: - 在验证数据上评估模型性能。 - 计算并存储当前 epoch 的验证损失。 - 如果当前 epoch 的验证损失优于之前的最佳验证损失,则保存当前模型的参数,并更新最佳验证损失。 5. **进度条信息更新**: - 在每个 epoch 的进度条中显示当前训练和验证损失。 执行期间截图如下所示  训练完毕后绘制训练过程中损失和验证损失随 epoch 变化的曲线图 ```php fig = plt.figure(figsize=(16, 8)) ax = fig.add_axes([0, 0, 1, 1]) ax.plot(np.arange(EPOCHS), losses) ax.plot(np.arange(EPOCHS), val_losses) ax.set_xlabel('epoch', fontsize='xx-large') ax.set_ylabel('log loss', fontsize='xx-large') ax.legend( ['loss', 'val loss'], loc='upper right', fontsize='xx-large', shadow=True ) plt.show() ``` 1. **图形和坐标轴初始化**: - 创建一个新的图形对象 `fig`,并指定图形的大小为 16x8 英寸。 - 使用 `fig.add_axes` 创建一个新的坐标轴 `ax`,并指定它占据整个图形区域。 2. **绘制损失曲线**: - 使用 `ax.plot` 绘制训练损失 `losses` 和验证损失 `val_losses` 随 epoch 变化的曲线。 - `np.arange(EPOCHS)` 生成一个从 0 到 `EPOCHS-1` 的整数数组,用作 x 轴数据。 3. **设置坐标轴标签**: - 使用 `ax.set_xlabel` 和 `ax.set_ylabel` 设置 x 轴和 y 轴的标签,字体大小为 `xx-large`。 4. **添加图例**: - 使用 `ax.legend` 添加图例,标注出训练损失和验证损失曲线。 - 图例的位置位于右上角 (`loc='upper right'`),字体大小为 `xx-large`,并带有阴影效果 (`shadow=True`)。 5. **显示图形**: - 使用 `plt.show` 显示绘制的图形。 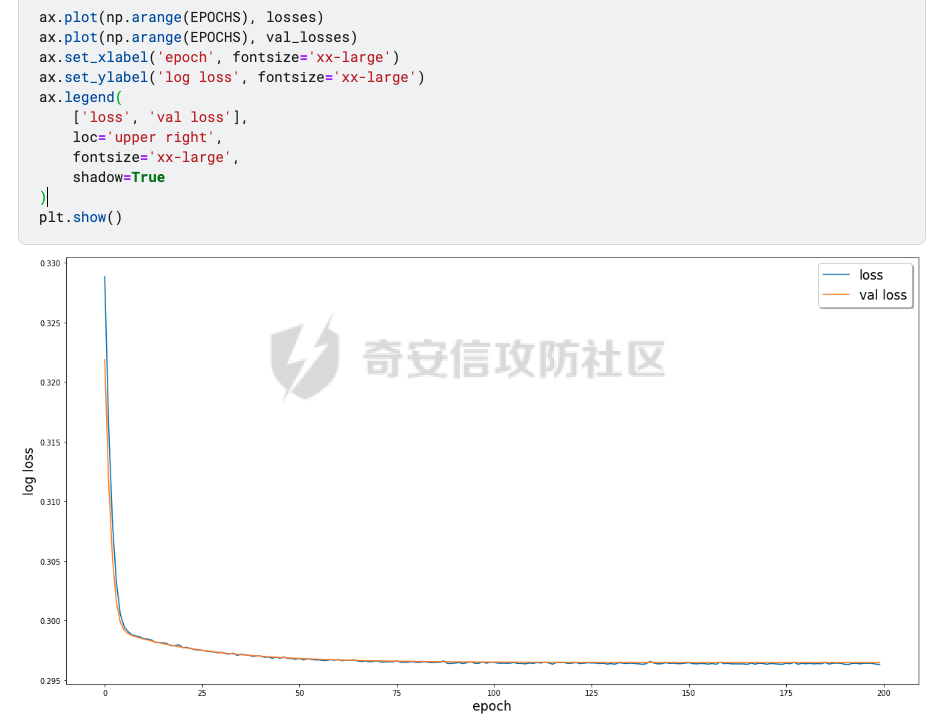 可以看到损失确实是有下降的,而且后期也趋向稳定 现在评估模型在验证数据上的性能,而不使用带权重的损失函数 ```php without_weight_criterion = nn.BCELoss(reduction='mean') classifier.eval() with torch.no_grad(): y_val_pred = classifier.predict(X_val) val_loss = without_weight_criterion(y_val_pred, y_val) print('val loss:', val_loss.detach().numpy()) ``` 1. **定义无权重损失函数**: - 创建一个二元交叉熵损失函数 `without_weight_criterion`,其减小方式为 `mean`,即平均损失。 2. **设置模型为评估模式**: - 使用 `classifier.eval()` 将模型设置为评估模式。这会关闭模型中的一些特性,如 dropout 和 batch normalization,以确保评估结果的稳定性。 3. **禁用梯度计算**: - 使用 `torch.no_grad()` 上下文管理器禁用梯度计算。这不仅可以减少内存使用,还能提高计算速度,因为在评估模型时不需要计算梯度。 4. **预测验证数据**: - 使用 `classifier.predict(X_val)` 生成验证数据的预测结果 `y_val_pred`。预测结果是经过 Sigmoid 函数处理的概率值。 5. **计算验证损失**: - 使用无权重的损失函数 `without_weight_criterion` 计算预测结果和实际标签 `y_val` 之间的损失 `val_loss`。 6. **打印验证损失**: - 将损失值转换为 numpy 数组,并打印验证损失。 执行后如下所示  可以看到使用逻辑回归方法取得了68.78%的伪造视频鉴别成功率。 参考 == 1.<https://www.bnext.com.tw/article/65676/ai-deepfake-gan-story-mooly> 2.<https://didit.me/blog/deepfake-what-it-is-how-it-s-created-and-why-you-should-be-cautious> 3.<https://theaisummer.com/deepfakes/> 4.<https://blog.metaphysic.ai/the-future-of-generative-adversarial-networks-in-deepfakes/> 5.<https://www.kaggle.com/>
发表于 2024-07-22 09:36:15
阅读 ( 9252 )
分类:
安全开发
1 推荐
收藏
0 条评论
elwood1916
28 篇文章
×
温馨提示
您当前没有「奇安信攻防社区」的账号,注册后可获取更多的使用权限。
×
温馨提示
您当前没有「奇安信攻防社区」的账号,注册后可获取更多的使用权限。
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!