LLVM Pass-PWN:从理论到实践,从入门到精通
内容包含LLVM Pass类PWN详细解读
环境搭建 ==== 我用kali本机只能下载有15和以上的,其他的缺少依赖项,懒得弄了,直接用docker搭建ubuntu20.04的可以下载 ```bash sudo apt install clang-8 sudo apt install llvm-8 sudo apt install clang-10 sudo apt install llvm-10 sudo apt install clang-12 sudo apt install llvm-12 ``` 基础知识 ==== 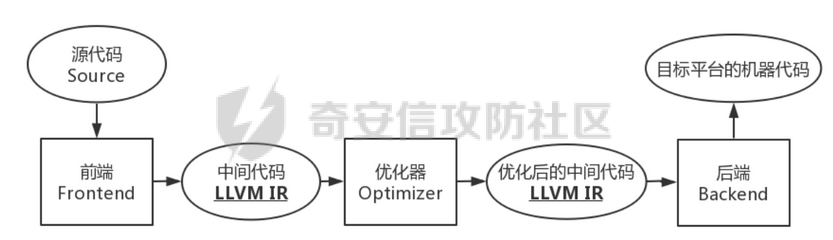 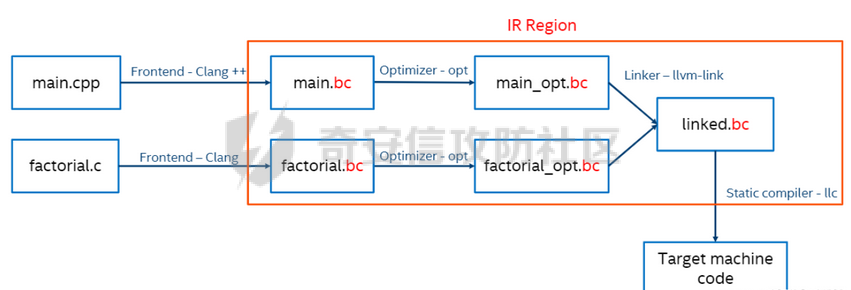  LLVM IR ------- LLVM IR即代码的中间表示,有三种形式: LLVM IR(Intermediate Representation,中间表示)是LLVM编译器框架中的一种中间代码表示形式。LLVM IR有三种主要的表示形式: 1. **.ll 格式**:人类可读的文本格式。 2. **.bc 格式**:适合机器存储和处理的二进制格式。 3. **内存表示**:LLVM编译器在运行时使用的内存中的数据结构。 ### 实例 假设我们有一个简单的C语言代码: ```c int add(int a, int b) { return a + b; } ``` 编译这个代码时,LLVM会将其转换为LLVM IR。我们可以通过不同的方式查看和存储这个LLVM IR。 #### 1. **.ll 格式(人类可读的文本格式)** 这是LLVM IR的文本表示形式,适合人类阅读和编辑。你可以通过命令行工具`clang`或`llvm-dis`生成这个格式。 ```llvm ; ModuleID = 'example.c' source_filename = "example.c" define i32 @add(i32 %a, i32 %b) { entry: %0 = add i32 %a, %b ret i32 %0 } ``` 在这个例子中: - `define i32 @add(i32 %a, i32 %b)` 定义了一个返回类型为`i32`(32位整数)的函数`add`,它有两个参数`a`和`b`,类型都是`i32`。 - `entry:` 是函数的入口基本块。 - `%0 = add i32 %a, %b` 表示将`a`和`b`相加,并将结果存储在临时变量`%0`中。 - `ret i32 %0` 返回结果`%0`。 #### 2. **.bc 格式(二进制格式)** 这是LLVM IR的二进制表示形式,适合机器存储和处理。它通常比文本格式更紧凑,适合在编译器内部传递或存储在磁盘上。 你可以通过`clang`或`llvm-as`工具生成这个格式: ```bash clang -emit-llvm -c example.c -o example.bc ``` 生成的`example.bc`文件是二进制格式,无法直接阅读,但可以通过`llvm-dis`工具将其转换回人类可读的`.ll`格式: ```bash llvm-dis example.bc -o example.ll ``` #### 3. **内存表示** 当LLVM编译器在运行时处理代码时,LLVM IR会以内存中的数据结构形式存在。这种表示形式是LLVM编译器内部使用的,通常是通过C++对象和数据结构来表示的。 例如,函数`add`在内存中可能表示为一个`llvm::Function`对象,基本块`entry`表示为一个`llvm::BasicBlock`对象,指令`%0 = add i32 %a, %b`表示为一个`llvm::Instruction`对象。 这些内存中的对象和数据结构允许LLVM进行各种优化和代码生成操作。开发者可以通过LLVM的C++ API来操作这些内存表示,例如添加、删除或修改指令,或者进行各种优化。 ```python .c -> .ll:clang -emit-llvm -S a.c -o a.ll .c -> .bc: clang -emit-llvm -c a.c -o a.bc .ll -> .bc: llvm-as a.ll -o a.bc .bc -> .ll: llvm-dis a.bc -o a.ll .bc -> .s: llc a.bc -o a.s ``` LLVM IR的处理 ========== LVM Pass可用于对代码进行优化或者对代码插桩(插入新代码),LLVM的核心库中提供了一些Pass类可以继承,通过实现它的一些方法,可以对传入的LLVM IR进行遍历并操作。 LLVM对IR中的函数、基本块(basic block)以及基本块内的指令的处理 ### 示例函数 假设我们有一个简单的 C 语言函数: ```c void example_function(int x, int y) { int result; if (x > y) { result = x + y; } else { result = x * y; } printf("The result is %d\n", result); } ``` ### 编译为 LLVM IR 将上述函数编译为 LLVM IR 可能会产生类似以下的中间表示: ```llvm define void @example_function(i32 %x, i32 %y) { entry: %result = alloca i32 %x_gt_y = icmp sgt i32 %x, %y br i1 %x_gt_y, label %iftrue, label %iffalse iftrue: %add_result = add i32 %x, %y br label %after_if iffalse: %mul_result = mul i32 %x, %y br label %after_if after_if: %phi_result = phi i32 [ %add_result, %iftrue ], [ %mul_result, %iffalse ] store i32 %phi_result, i32* %result %print_result = call void @printf(i8* getelementptr inbounds ([17 x i8], [17 x i8]* @.str, i32 0, i32 0), i32 %phi_result) ret void @.str = private unnamed_addr constant [17 x i8] c"The result is %d\n\00" ``` ### 解释 - **函数(Function)**: `@example_function` 是一个函数,它接受两个整数参数 `x` 和 `y` 并打印它们的运算结果。 - **基本块(Basic Block)**: 一个基本块是一段连续的指令序列,控制流不能从中中断。在这个示例中,我们有三个基本块: - `entry`: 函数的入口点,分配局部变量空间并进行条件跳转。 - `iftrue`: 当 `x > y` 时执行的代码块。 - `iffalse`: 当 `x <= y` 时执行的代码块。 - `after_if`: 无论哪个条件分支被执行之后的合并点。 - **基本块内的指令(Instructions)**: 每个基本块包含了一系列的指令。例如,在 `entry` 基本块中,我们有: - `%result = alloca i32`:分配一个整数类型的局部变量 `result`。 - `%x_gt_y = icmp sgt i32 %x, %y`:比较 `x` 是否大于 `y`。 - `br i1 %x_gt_y, label %iftrue, label %iffalse`:根据条件跳转到 `iftrue` 或者 `iffalse` 基本块。 在 `iftrue` 基本块中,我们有: - `%add_result = add i32 %x, %y`:如果 `x > y`,则计算 `x + y`。 - `br label %after_if`:无条件跳转到 `after_if` 基本块。 在 `iffalse` 基本块中,我们有: - `%mul_result = mul i32 %x, %y`:如果 `x <= y`,则计算 `x * y`。 - `br label %after_if`:无条件跳转到 `after_if` 基本块。 在 `after_if` 基本块中,我们有: - `%phi_result = phi i32 [ %add_result, %iftrue ], [ %mul_result, %iffalse ]`:选择 `iftrue` 或 `iffalse` 中的结果作为最终结果。 - `store i32 %phi_result, i32* %result`:将结果存储到局部变量 `result` 中。 - `%print_result = call void @printf(...)`:调用 `printf` 函数打印结果。 - `ret void`:返回空值,结束函数。 流程 == - LLVM PASS就是去处理IR文件,通过opt利用写好的so库优化已有的IR,形成新的IR。 - LLVM PASS类PWN就是opt加载pass.so文件,对IR代码进行转换和优化这个过程中存在的漏洞加以利用。这里需要注意的是.so文件是不会被pwn的,我们pwn的是加载.so文件的程序——opt。所以我们需要对opt进行常规的检查。 CTF题目一般会给出所需版本的opt文件(可用./opt --version查看版本)或者在README文档中告知opt版本。安装好llvm后,可在/usr/lib/llvm-xx/bin/opt路径下找到对应llvm版本的opt文件(一般不开PIE保护)。 搜索vtable定位到虚表,最下面的函数就是重写的虚函数runOnFunction 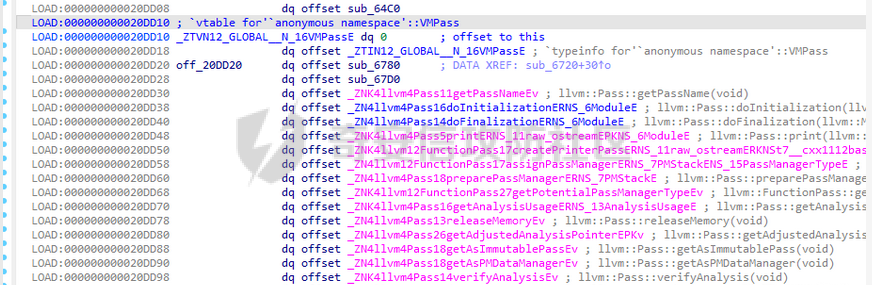 调试 == ```bash clang-8 -emit-llvm -S exp.c -o exp.bc或者 clang-8 -emit-llvm -S exp.c -o exp.ll ``` ```bash opt-8 -load ./VMPass.so -VMPass ./exp.bc ``` 调试opt然后跟进到so文件  opt并不会一开始就将so模块加载进来,会执行一些初始化函数才会加载so模块。 调试的时候可以把断点下载llvm::Pass::preparePassManager,程序执行到这里的时候就已经加载了LLVMHello.so文件(或者到main+11507),我们就可以根据偏移进一步将断点下在LLVMHello.so文件里面 查看vmmap,发现已经加载进来,然后可以更加偏移断在runOnFunction上 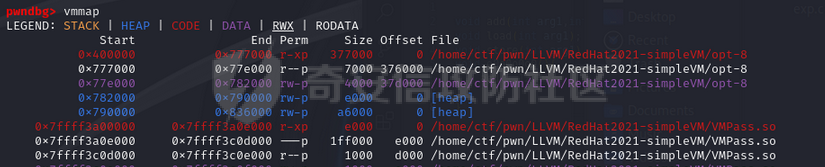  成功  使用脚本 ```python from pwn import * import sys import os os.system("clang-8 -emit-llvm -S exp.c -o exp.bc") p = gdb.debug(["./opt-8",'-load','./VMPass.so','-VMPass','./exp.bc'],"b llvm::Pass::preparePassManager\nc") p.interactive() ``` IR结构 ==== [LLVM IR数据结构分析](https://akaieurus.github.io/2023/10/02/LLVM-IR%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%88%86%E6%9E%90/) LLVMContext ----------- - 一个全局数据 - 只能通过`llvm::getGlobalContext();`创建赋值给一个`LLVMContext`变量 - 删除了拷贝构造函数和拷贝赋值函数 moudle ------ - 主要是包含函数和全局变量的两个链表 - 创建一个Module,需要一个名字和一个LLVMContext - Module操作函数链表的成员函数 `begin() end () size() empty() functions()`,直接拿到函数链表的函数`getFunctionList()`,查找模块内函数链表中函数的函数`getFunction` ```c iterator_range functions() { return make_range(begin(), end()); } FunctionListType &getFunctionList() { return FunctionList; } Function *getFunction(StringRef Name) const; ``` - -Module操作全局变量的成员函数 `global_begin() global_end () global_size() global_empty() globals()`直接拿到全局变量链表的函数`getGlobalList()` ```c iterator_range globals() { return make_range(global_begin(), global_end()); } GlobalListType &getGlobalList() { return GlobalList; } ``` - 插入或查找函数 `StringRef Name:函数名 Type *RetTy:返回值类型 ArgsTy… Args:每个参数的类型 FunctionType *T:函数类型(其实就是参数类型和返回值类型的集合),可以通过get方法构造 isVarArg:是是否支持可变参数` ```c FunctionCallee getOrInsertFunction(StringRef Name, FunctionType *T); template FunctionCallee getOrInsertFunction(StringRef Name, Type *RetTy, ArgsTy... Args); 返回值类型是FunctionCallee,成员为一个Value指针(就是具体的函数Function 指针)和一个FunctionType指针 class FunctionCallee { private: FunctionType *FnTy = nullptr; Value *Callee = nullptr; }; 可通过如下方法获得 FunctionType *getFunctionType() { return FnTy; } Value *getCallee() { return Callee; } FunctionType 只是一个函数类型信息 class FunctionType : public Type { static FunctionType *get(Type *Result, ArrayRef Params, bool isVarArg); Function 才是具体的函数 FunctionCallee Module::getOrInsertFunction(StringRef Name, FunctionType *Ty, AttributeList AttributeList) { // See if we have a definition for the specified function already. GlobalValue *F = getNamedValue(Name); if (!F) { // Nope, add it Function *New = Function::Create(Ty, GlobalVariable::ExternalLinkage, DL.getProgramAddressSpace(), Name); if (!New->isIntrinsic()) // Intrinsics get attrs set on construction New->setAttributes(AttributeList); FunctionList.push_back(New); return {Ty, New}; // Return the new prototype. } 但使用由于原来是 Value *会需要转换 Function *customFunc = dyn_cast(callee.getCallee()); ``` Value,User和Use -------------- 刚看的时候真抽象 - User用Value,这个使用的行为就是Use,同时Value里面有个Uselist记录了哪些User用过它们 ```c class Value { Use *UseList; …… } 使用Value的Use以双向链表连接起来 class Use { private: Value *Val = nullptr; Use *Next = nullptr; Use **Prev = nullptr; User *Parent = nullptr; Val:指向被使用的Value Next:指向下一个Use Prev:指向上一个Prev Parent:指向User ``` - Use会放在User结构体前,一种是以固定个数的Use,以数组的形式放在User前,另一种是不定个数的Use,一个Use放在User前,这个Use的Prev指针指向Use数组,然后可以通过一个Use找到其他Use,通过`getOperandList`的不同处理可以看出 ```c // HasHungOffUses是Value的成员 const Use *getOperandList() const { return HasHungOffUses ? getHungOffOperands() : getIntrusiveOperands(); } const Use *getHungOffOperands() const { return *(reinterpret_cast(this) - 1); } const Use *getIntrusiveOperands() const { return reinterpret_cast(this) - NumUserOperands; } ``` GlobalVariable -------------- - GlobalVariable由GlobalObject和ilist\_node\_base组成 - GlobalObject是一个容器,其中的GlobalValue包含了Value、ValueType、Parent等属性 - Globallist中的prev和next和GlobalVariable中的ilist\_node\_base双向连接  - 通过GlobalVariable创建,下面一种方式除了创建还会将该GlobalVariable添加到模块中,同时禁止了拷贝构造函数和赋值 ```c GlobalVariable(Type *Ty, bool isConstant, LinkageTypes Linkage, Constant *Initializer = nullptr, const Twine &Name = "", ThreadLocalMode = NotThreadLocal, unsigned AddressSpace = 0, bool isExternallyInitialized = false); GlobalVariable(Module &M, Type *Ty, bool isConstant, LinkageTypes Linkage, Constant *Initializer, const Twine &Name = "", GlobalVariable *InsertBefore = nullptr, ThreadLocalMode = NotThreadLocal, Optional AddressSpace = None, bool isExternallyInitialized = false); GlobalVariable(const GlobalVariable &) = delete; GlobalVariable &operator=(const GlobalVariable &) = delete; ``` Function -------- - 包含GlobalObject和illst\_node\_base和一个Arguments指针,指向Argument数组,一个BasicBlock双链表  - BasicBlock迭代器:`begin() end() size() empty() &front() &back()` begin返回指向BasicBlock集合的第一个元素的迭代器。front是第一个元素的引用。end和back同理 - Argument迭代器:`arg_begin() arg_end() getArg(unsigned i) args()` ```c 返回一个迭代器范围 iterator_range args() { return make_range(arg_begin(), arg_end()); } ``` - Function创建 ```c static Function *Create(FunctionType *Ty, LinkageTypes Linkage, const Twine &N, Module &M); static Function *Create(FunctionType *Ty, LinkageTypes Linkage, unsigned AddrSpace, const Twine &N = "", Module *M = nullptr) { return new Function(Ty, Linkage, AddrSpace, N, M); } static Function *Create(FunctionType *Ty, LinkageTypes Linkage, const Twine &N = "", Module *M = nullptr) { return new Function(Ty, Linkage, static_cast(-1), N, M); } ``` - FunctionType是Type的子类,ReturnType和ParamType都存在Type类型的ContainedTys成员里,这是一个Type数组 ```c class Type { protected: unsigned NumContainedTys = 0; Type * const *ContainedTys = nullptr; ``` 可以从getXXXType函数中看出来 ```c // Function Type *getReturnType() const { return getFunctionType()->getReturnType(); } // FunctionType FunctionType *getFunctionType() const { return cast(getValueType()); } Type *getReturnType() const { return ContainedTys[0]; } Type *getParamType(unsigned i) const { return ContainedTys[i+1]; } ``` 对于函数的入口的basicblock ```c const BasicBlock &getEntryBlock() const { return front(); } BasicBlock &getEntryBlock() { return front(); } ``` - 设置和获取函数调用规定 `getCallingConv()`:返回Function的调用约定。 `setCallingConv(CC)`:设置Function的调用约定为`CC`。 `CallingConv::ID`是一个枚举类型,表示不同的调用约定。 `getSubclassDataFromValue()`是一个内部函数,用于从Function对象中提取一些数据。在这个例子中,它返回了Function的一些位掩码,其中的一部分表示调用约定。 `getCallingConv()`通过移位和按位与运算从这些位掩码中提取出调用约定的值。 `setCallingConv(CC)`首先将`CC`转换为无符号整数,然后检查它是否在一个有效的范围内。如果有效,它会更新Function的位掩码以反映新的调用约定。 ```c CallingConv::ID getCallingConv() const { return static_cast((getSubclassDataFromValue() >> 4) & CallingConv::MaxID); } void setCallingConv(CallingConv::ID CC) { auto ID = static_cast(CC); assert(!(ID & ~CallingConv::MaxID) && "Unsupported calling convention"); setValueSubclassData((getSubclassDataFromValue() & 0xc00f) | (ID << 4)); } ``` BasicBlock ---------- - BasicBlock内包括Value和ilist\_node\_base和Instlist和Parent,Instlist包含指令链表 - 创建一个BasicBlock 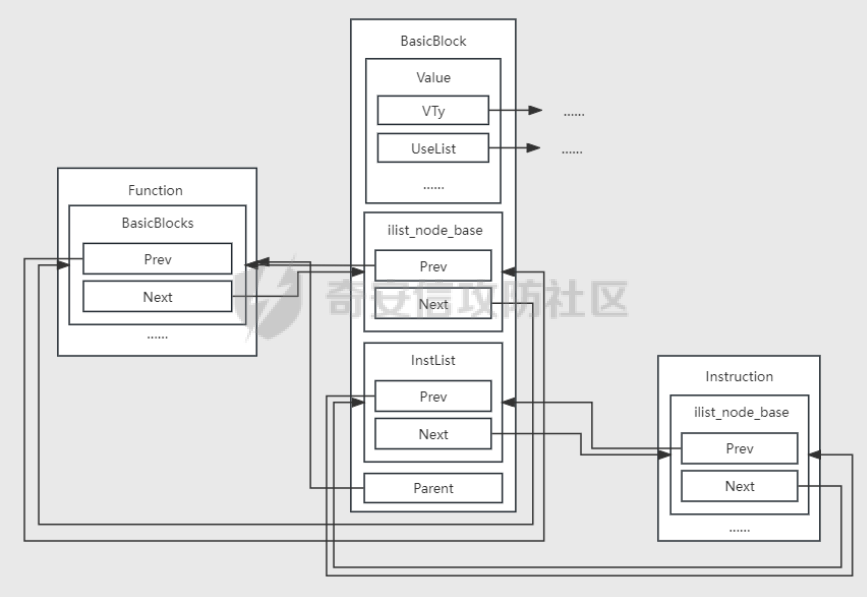 ```c static BasicBlock *Create(LLVMContext &Context, const Twine &Name = "", Function *Parent = nullptr, BasicBlock *InsertBefore = nullptr) { return new BasicBlock(Context, Name, Parent, InsertBefore); } 当InsertBefore为NULL时默认插入Function末尾 BasicBlock::BasicBlock(LLVMContext &C, const Twine &Name, Function *NewParent, BasicBlock *InsertBefore) : Value(Type::getLabelTy(C), Value::BasicBlockVal), Parent(nullptr) { if (NewParent) // Insert unlinked basic block into a function. Inserts an unlinked basic block into Parent. If InsertBefore is provided, inserts before that basic block, otherwise inserts at the end. insertInto(NewParent, InsertBefore); else assert(!InsertBefore && "Cannot insert block before another block with no function!"); setName(Name); } ``` - Instruction迭代器:`begin() end() rbegin() rend() size() empty() front() back()` 获取Instruction所属Function ```c const Function *getParent() const { return Parent; } Function *getParent() { return Parent; } ``` Instruction ----------- - 包含Value和illist\_node\_base和Parent 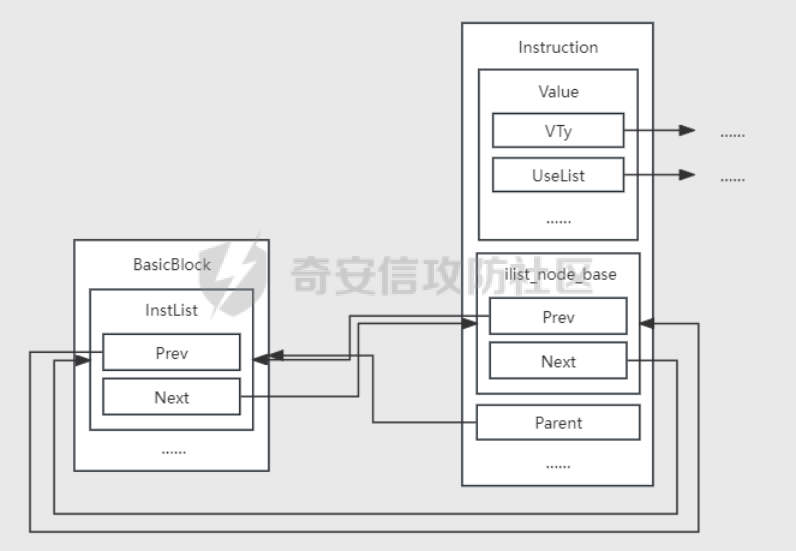 - 获取父BasicBlock ```c inline const BasicBlock *getParent() const { return Parent; } inline BasicBlock *getParent() { return Parent; } ``` - 获取指令的操作码 ```c unsigned getOpcode() const { return getValueID() - InstructionVal; } ``` - 返回指令的另一个实例 没有名字: 在LLVM中,值(包括指令)可以有名字,用于调试和识别。克隆的指令不会自动获得原指令的名字,所以它是匿名的。 没有Parent: 克隆的指令不属于任何BasicBlock。在LLVM中,指令是包含在BasicBlock中的,而BasicBlock又属于Function。一个新克隆的指令还没有被插入到任何BasicBlock中,因此它的Parent(即它所在的BasicBlock)是nullptr。 ```c Instruction *clone() const; ``` - 指令替换 ```cpp void ReplaceInstWithInst(BasicBlock::InstListType &BIL, BasicBlock::iterator &BI, Instruction *I); - `BIL`: 这是`BasicBlock`的指令列表,代表了指令所在的序列。 - `BI`: 这是指向要被替换指令的迭代器。 - `I`: 这是要替换成的新指令。 ``` ```cpp void ReplaceInstWithInst(Instruction *From, Instruction *To); // 不更新迭代器,会段错误 - **参数解释**: - `From`: 要被替换的旧指令。 - `To`: 新的指令。 ``` 不同Instruction的创建 ---------------- alloca ------ ### alloca命令是AllocaInst类型,继承关系是 - alloca命令是AllocaInst类型,继承关系是 ```c AllocaInst->UnaryInstruction->Instruction ``` `AllocaInst` 是 LLVM 中用来表示栈上内存分配指令的类。它是继承自 `UnaryInstruction` 和 `Instruction` 的一个子类。它的主要作用是在当前函数的栈帧上分配内存空间,通常用于存储局部变量。 下面是一些关于如何使用 `AllocaInst` 类的详细说明和示例: ### 类的继承关系 `AllocaInst` 是 `Instruction` 的子类,具体继承关系如下: - `AllocaInst` -> `UnaryInstruction` -> `Instruction` -> `User` -> `Value` ### `AllocaInst` 的构造函数 `AllocaInst` 提供了多个构造函数,允许你在创建对象时指定不同的参数。常用的构造函数包括: 1. **类型和地址空间** ```cpp AllocaInst(Type *Ty, unsigned AddrSpace, const Twine &Name, Instruction *InsertBefore); AllocaInst(Type *Ty, unsigned AddrSpace, const Twine &Name, BasicBlock *InsertAtEnd); ``` 2. **类型、地址空间和数组大小** ```cpp AllocaInst(Type *Ty, unsigned AddrSpace, Value *ArraySize, Align Align, const Twine &Name = "", Instruction *InsertBefore = nullptr); AllocaInst(Type *Ty, unsigned AddrSpace, Value *ArraySize, Align Align, const Twine &Name, BasicBlock *InsertAtEnd); ``` ### 参数说明 - \**`Type* Ty`\*\*: 要分配的内存类型。 - **`unsigned AddrSpace`**: 地址空间,可以通过 `Module` 的 `getDataLayout().getAllocaAddrSpace()` 方法获取。 - \**`Value* ArraySize`**: 数组大小,通常使用`ConstantInt` 表示单个元素时大小为 1。 - **`Align Align`**: 内存对齐,可以指定对齐值。 - **`const Twine &Name`**: 指令的名称。 - \**`Instruction* InsertBefore`\*\*: 将新指令插入到某个指令之前。 - \**`BasicBlock* InsertAtEnd`\*\*: 将新指令插入到基本块结束处。 ### 使用示例 #### 创建一个 `AllocaInst` ```cpp // 创建一个上下文 LLVMContext context; // 获取数据布局和地址空间 Module *module = /* 获取或创建一个 Module */; unsigned addrSpace = module->getDataLayout().getAllocaAddrSpace(); // 创建一个基本块 BasicBlock *entryBlock = /* 获取或创建一个 BasicBlock */; // 创建一个常量整数,表示数组大小 Value* intValue = ConstantInt::get(context, APInt(32, 1)); // 创建 AllocaInst 实例 AllocaInst *allocaInst = new AllocaInst( IntegerType::get(context, 32), // 类型为 int32 addrSpace, // 地址空间 intValue, // 数组大小 Align(4), // 对齐 "", // 名称 entryBlock // 插入位置 ); // 设置对齐 allocaInst->setAlignment(Align(4)); ``` ### 解释 - **地址空间**: 通过 `Module` 的 `DataLayout` 获取到 `AllocaAddrSpace`。 - **数组大小**: 使用 `ConstantInt::get` 创建 `ConstantInt` 表示分配单个元素。 - **对齐**: 可以在构造时指定对齐,也可以之后通过 `setAlignment` 设置。 这种用法在 LLVM IR 中生成如下指令: ```php %1 = alloca i32, align 4 ``` store ----- 在LLVM中,`StoreInst` 是一种用于执行存储操作的指令,表示将一个值存储到指定的内存位置。它继承自 `Instruction` 类,并且比 `Instruction` 多了一个 `SSID` 成员,用于表示同步作用域(`SyncScope::ID`),这在多线程环境中非常重要。 ### 1. `StoreInst` 的继承结构 `StoreInst` 继承自 `Instruction`,因此它包含了 `Instruction` 类的所有成员,并且额外增加了一个 `SSID` 成员。`SSID` 是 `SyncScope::ID` 类型的,它用于指定同步范围(如系统范围或单线程范围),在存储操作涉及到线程同步时,这个字段会派上用场。 ### 2. `StoreInst` 的构造函数 `StoreInst` 提供了多个构造函数,允许用户创建包含不同参数的存储指令。常见的构造函数如下: - `StoreInst(Value *Val, Value *Ptr, Instruction *InsertBefore);` - `StoreInst(Value *Val, Value *Ptr, BasicBlock *InsertAtEnd);` - `StoreInst(Value *Val, Value *Ptr, bool isVolatile, Instruction *InsertBefore);` - `StoreInst(Value *Val, Value *Ptr, bool isVolatile, BasicBlock *InsertAtEnd);` - `StoreInst(Value *Val, Value *Ptr, bool isVolatile, Align Align, Instruction *InsertBefore = nullptr);` - `StoreInst(Value *Val, Value *Ptr, bool isVolatile, Align Align, BasicBlock *InsertAtEnd);` - `StoreInst(Value *Val, Value *Ptr, bool isVolatile, Align Align, AtomicOrdering Order, SyncScope::ID SSID = SyncScope::System, Instruction *InsertBefore = nullptr);` - `StoreInst(Value *Val, Value *Ptr, bool isVolatile, Align Align, AtomicOrdering Order, SyncScope::ID SSID, BasicBlock *InsertAtEnd);` 这些构造函数的参数通常包括: - `Val`:要存储的值。 - `Ptr`:存储目标(即内存地址)。 - `isVolatile`:是否为易失性存储。若为 `true`,编译器在优化过程中不能移除或重新排序此存储操作。 - `Align`:对齐方式。 - `AtomicOrdering`:原子操作的顺序(如顺序一致性、获取-释放等)。 - `SSID`:同步作用域的ID,默认是系统范围的 `SyncScope::System`。 - `InsertBefore` 和 `InsertAtEnd`:指定指令插入的位置,可以是插入到某一指令之前或某个基本块的末尾。 ### 3. 代码示例 ```cpp StoreInst *st0 = new StoreInst(param1, ptr4, false, entryBlock); st0->setAlignment(Align(4)); ``` - `param1`: 是一个指向 `Value` 的指针,表示要存储的值。 - `ptr4`: 是一个指向 `Value` 的指针,表示存储的目标地址,也就是 `param1` 将被存储到这个地址中。 - `false`: 表示这个存储操作不是易失性的(非 `volatile`)。 - `entryBlock`: 是一个 `BasicBlock`,表示指令将插入到这个基本块的末尾。 - `st0->setAlignment(Align(4))`: 设置存储操作的对齐方式为 4 字节。 ### 4. 解释 这段代码的作用是创建一个 `StoreInst` 对象,该对象表示将 `param1` 的值存储到 `ptr4` 指向的内存地址中,并且这个存储操作将被插入到基本块 `entryBlock` 的末尾。 - `StoreInst *st0 = new StoreInst(param1, ptr4, false, entryBlock);`: 这行代码创建了一个新的 `StoreInst` 实例,表示将 `param1` 存储到 `ptr4` 中,并将其插入到 `entryBlock` 的末尾。 - `st0->setAlignment(Align(4));`: 这行代码设置了存储操作的对齐方式为 4 字节。对齐方式在内存操作中很重要,特别是在处理不同架构和优化时。 load ==== 在LLVM中,`LoadInst` 是一种用于从内存中加载值的指令。与 `StoreInst` 类似,`LoadInst` 继承自 `Instruction`,并且比 `Instruction` 多了一个 `SSID` 成员,用于表示同步作用域(`SyncScope::ID`)。这个成员在多线程环境中非常重要,因为它用于指定加载操作的同步范围。 ### 1. `LoadInst` 的继承结构 `LoadInst` 继承自 `UnaryInstruction`,而 `UnaryInstruction` 继承自 `Instruction`。`LoadInst` 比 `Instruction` 多了一个 `SSID` 成员,它用于指定同步作用域。这在处理多线程程序时非常关键,特别是涉及到原子操作和内存序列时。 ### 2. `LoadInst` 的构造函数 `LoadInst` 提供了多种构造函数,允许根据不同的需求来创建加载指令。常见的构造函数包括: - `LoadInst(Type *Ty, Value *Ptr, const Twine &NameStr, Instruction *InsertBefore);` - `LoadInst(Type *Ty, Value *Ptr, const Twine &NameStr, BasicBlock *InsertAtEnd);` - `LoadInst(Type *Ty, Value *Ptr, const Twine &NameStr, bool isVolatile, Instruction *InsertBefore);` - `LoadInst(Type *Ty, Value *Ptr, const Twine &NameStr, bool isVolatile, BasicBlock *InsertAtEnd);` - `LoadInst(Type *Ty, Value *Ptr, const Twine &NameStr, bool isVolatile, Align Align, Instruction *InsertBefore = nullptr);` - `LoadInst(Type *Ty, Value *Ptr, const Twine &NameStr, bool isVolatile, Align Align, BasicBlock *InsertAtEnd);` - `LoadInst(Type *Ty, Value *Ptr, const Twine &NameStr, bool isVolatile, Align Align, AtomicOrdering Order, SyncScope::ID SSID = SyncScope::System, Instruction *InsertBefore = nullptr);` - `LoadInst(Type *Ty, Value *Ptr, const Twine &NameStr, bool isVolatile, Align Align, AtomicOrdering Order, SyncScope::ID SSID, BasicBlock *InsertAtEnd);` 这些构造函数的参数意义如下: - `Ty`: 加载数据的类型。 - `Ptr`: 指向要从中加载数据的内存位置的指针。 - `NameStr`: 指令的名称(通常用于调试)。 - `isVolatile`: 是否为易失性加载操作。若为 `true`,编译器在优化过程中不能移除或重新排序此加载操作。 - `Align`: 对齐方式。 - `AtomicOrdering`: 原子操作的顺序(如顺序一致性、获取-释放等)。 - `SSID`: 同步作用域的ID,默认是系统范围的 `SyncScope::System`。 - `InsertBefore` 和 `InsertAtEnd`: 指定指令插入的位置,可以是插入到某一指令之前或某个基本块的末尾。 ### 3. 代码示例 ```cpp LoadInst *ld0 = new LoadInst(IntegerType::get(context, 32), ptr4, "",false, entryBlock); ld0->setAlignment(Align(4)); ``` - `IntegerType::get(context, 32)`: 创建一个32位宽的整数类型。 - `ptr4`: 是一个指向 `Value` 的指针,表示要从中加载数据的内存地址。 - `""`: 表示指令的名称为空字符串。 - `false`: 表示这个加载操作不是易失性的(非 `volatile`)。 - `entryBlock`: 是一个 `BasicBlock`,表示指令将插入到这个基本块的末尾。 `ld0->setAlignment(Align(4))`: 设置加载操作的对齐方式为4字节。 add --- 在LLVM中,`BinaryOperator` 是一个用于表示二元算术操作(如加法、减法、乘法等)的类。它继承自 `Instruction` 类,并且不引入额外的数据成员(即没有自己的 data 域)。`BinaryOperator` 主要用于创建和管理二元运算指令。 ### 1. `BinaryOperator` 的创建 `BinaryOperator` 提供了静态工厂方法 `Create`,用于创建具体的二元操作指令。常用的两个 `Create` 方法如下: ```cpp static BinaryOperator *Create(BinaryOps Op, Value *S1, Value *S2, const Twine &Name = Twine(), Instruction *InsertBefore = nullptr); static BinaryOperator *Create(BinaryOps Op, Value *S1, Value *S2, const Twine &Name, BasicBlock *InsertAtEnd); ``` - **`Op`**: 表示要执行的二元操作类型,这个类型是 `BinaryOps` 枚举值。例如,加法操作是 `Instruction::Add`。 - **`S1` 和 `S2`**: 这是两个操作数,通常是指向 `Value` 对象的指针,表示要参与运算的值。 - **`Name`**: 是一个 `Twine` 类型的对象,用于设置操作指令的名称。这个参数是可选的,通常用于生成更具可读性的LLVM IR代码。 - **`InsertBefore`**: 指定将这条指令插入到现有指令之前。 - **`InsertAtEnd`**: 指定将这条指令插入到基本块的末尾。 ### 2. `BinaryOps` 枚举 `BinaryOps` 是一个枚举类型,它定义了所有的二元操作指令类型。这个枚举包括了各种常见的操作符,如加法 (`Add`)、减法 (`Sub`)、乘法 (`Mul`)、除法 (`Div`) 等。 枚举的定义通常在 `Instruction.def` 文件中通过宏展开生成,例如: ```cpp enum BinaryOps { #define FIRST_BINARY_INST(N) BinaryOpsBegin = N, #define HANDLE_BINARY_INST(N, OPC, CLASS) OPC = N, #define LAST_BINARY_INST(N) BinaryOpsEnd = N+1 #include "llvm/IR/Instruction.def" }; ``` 其中 `Instruction::Add` 是一个 `BinaryOps` 枚举值,表示加法操作。 ### 3. 代码示例解析 ```cpp BinaryOperator *add1 = BinaryOperator::Create(Instruction::Add, ld0, ld1, "", entryBlock); ``` - **`Instruction::Add`**: 这是一个 `BinaryOps` 枚举值,表示加法操作。 - **`ld0` 和 `ld1`**: 这两个值分别是两个操作数,通常是 `Value*` 类型的指针,表示要相加的两个值。这些值可能是从之前的 `LoadInst` 或其他指令中获取的。 - **`""`**: 这是指令的名称,用于生成的LLVM IR中。如果没有特别指定,可以留空字符串。 - **`entryBlock`**: 这是一个指向 `BasicBlock` 的指针,表示将指令插入到该基本块的末尾。 ### 4. 解释 这段代码的作用是创建一个加法操作的 `BinaryOperator` 对象,表示将 `ld0` 和 `ld1` 这两个操作数相加,并将生成的加法指令插入到 `entryBlock` 基本块的末尾。 - **创建加法指令**: `BinaryOperator::Create(Instruction::Add, ld0, ld1, "", entryBlock)` 创建了一个加法指令,将 `ld0` 和 `ld1` 相加。 - **插入基本块**: 这个加法指令会被插入到 `entryBlock` 的末尾。 这条指令对应的LLVM IR可能类似于: ```llvm %add1 = add i32 %ld0, %ld1 ``` - `%add1` 是生成的加法指令的结果。 - `i32` 表示操作数是32位整数。 - `%ld0` 和 `%ld1` 是要相加的两个操作数。 icmp ---- 在LLVM中,`ICmpInst` 是用于表示整数比较操作的指令。它继承自 `CmpInst`,并且没有增加额外的数据成员。`ICmpInst` 使用 `Predicate` 来指定具体的比较类型,例如等于、不等于、大于、小于等。 ### 1. `ICmpInst` 的构造函数 `ICmpInst` 提供了多个构造函数,用于创建整数比较指令。这些构造函数的作用是生成一条比较指令,将其插入到指定的位置(例如某个基本块的末尾)。 以下是构造函数原型的详细说明: ```cpp ICmpInst( Instruction *InsertBefore, // 要插入的指令之前的位置 Predicate pred, // 比较谓词,表示比较类型 Value *LHS, // 左操作数 Value *RHS, // 右操作数 const Twine &NameStr = "" // 指令名称 ) ``` - **`InsertBefore`**: 指定将比较指令插入到哪条现有指令之前。 - **`pred`**: 指定比较的类型,例如 `ICMP_EQ` 表示等于,`ICMP_SGT` 表示有符号大于等。 - **`LHS`**: 左操作数(通常是一个 `Value` 指针)。 - **`RHS`**: 右操作数(通常是一个 `Value` 指针)。 - **`NameStr`**: 可选参数,指令的名称,通常用于调试或生成的LLVM IR的可读性。 ### 2. `Predicate` 枚举 `Predicate` 枚举定义了所有可能的比较操作符。对于整数比较,常见的值包括: - **`ICMP_EQ`**: 等于 - **`ICMP_NE`**: 不等于 - **`ICMP_UGT`**: 无符号大于 - **`ICMP_UGE`**: 无符号大于或等于 - **`ICMP_ULT`**: 无符号小于 - **`ICMP_ULE`**: 无符号小于或等于 - **`ICMP_SGT`**: 有符号大于 - **`ICMP_SGE`**: 有符号大于或等于 - **`ICMP_SLT`**: 有符号小于 - **`ICMP_SLE`**: 有符号小于或等于 这些枚举值用于指定在比较操作中应该执行哪种类型的比较。 ### 3. 代码示例解析 ```cpp ICmpInst *icmp = new ICmpInst( *entryBlock, // 指令插入的基本块 ICmpInst::ICMP_SGT, // 使用有符号大于的比较 add1, // 左操作数 ConstantInt::get(context, APInt(32, 100)), // 右操作数,常量100 "" ); ``` - \**`*entryBlock`**: 这表示要将指令插入到`entryBlock` 基本块的末尾。 - **`ICmpInst::ICMP_SGT`**: 这里指定了有符号大于 (`signed greater than`) 的比较谓词,表示将比较 `add1` 和 `100`,判断 `add1` 是否大于 `100`。 - **`add1`**: 这是左操作数,通常是一个 `Value*` 类型的指针,它可能是之前某个计算指令的结果。 - **`ConstantInt::get(context, APInt(32, 100))`**: 这是右操作数,表示一个32位宽、值为100的常量整数。`ConstantInt::get` 生成一个 `ConstantInt` 对象,这是LLVM中表示常量整数的方式。 ### 4. 解释 这段代码的作用是创建一条整数比较指令,它会判断 `add1` 是否大于100。假设 `add1` 的类型是32位整数,那么生成的LLVM IR指令可能类似于: ```llvm %cmp = icmp sgt i32 %add1, 100 ``` - `%cmp` 是生成的比较指令的结果。 - `icmp sgt i32` 表示这是一个有符号大于(signed greater than)的比较操作。 - `%add1` 是左操作数,`100` 是右操作数。 branch ------ 在LLVM中,`BranchInst` 是用于表示分支(跳转)操作的指令。`BranchInst` 没有额外的数据成员(即没有自己的 data 域),它的所有状态和行为都通过继承自 `Instruction` 类来实现。`BranchInst` 可以表示无条件分支(跳转到一个目标块)或者有条件分支(根据条件选择跳转到不同的目标块)。 ### 1. `BranchInst` 的创建方法 `BranchInst` 提供了多个静态方法 `Create`,用于创建分支指令。具体的方法如下: - **无条件分支**: 只跳转到一个目标块。 ```cpp static BranchInst *Create(BasicBlock *IfTrue, Instruction *InsertBefore = nullptr); static BranchInst *Create(BasicBlock *IfTrue, BasicBlock *InsertAtEnd); ``` - **`IfTrue`**: 目标基本块,指定无条件跳转的目的地。 - **`InsertBefore`**: 将指令插入到指定的现有指令之前。 - **`InsertAtEnd`**: 将指令插入到指定基本块的末尾。 - **有条件分支**: 根据条件跳转到不同的目标块。 ```cpp static BranchInst *Create(BasicBlock *IfTrue, BasicBlock *IfFalse, Value *Cond, Instruction *InsertBefore = nullptr); static BranchInst *Create(BasicBlock *IfTrue, BasicBlock *IfFalse, Value *Cond, BasicBlock *InsertAtEnd); ``` - **`IfTrue`**: 条件为真的时候跳转的目标块。 - **`IfFalse`**: 条件为假的时候跳转的目标块。 - **`Cond`**: 条件值(通常是一个比较结果,例如 `ICmpInst` 的结果)。 - **`InsertBefore`**: 将指令插入到指定的现有指令之前。 - **`InsertAtEnd`**: 将指令插入到指定基本块的末尾。 ### 2. 代码示例解析 ```cpp BranchInst::Create(block10, block19, icmp, entryBlock); ``` - **`block10`**: 这是条件为真时将要跳转的目标基本块。 - **`block19`**: 这是条件为假时将要跳转的目标基本块。 - **`icmp`**: 这是条件值,通常是一个 `Value*`,表示分支条件。在这个例子中,它可能是一个 `ICmpInst` 的结果。 - **`entryBlock`**: 这是一个 `BasicBlock*`,指定将该分支指令插入到的基本块。在这个例子中,分支指令会插入到 `entryBlock` 的末尾。 ### 3. 解释 这段代码的作用是创建一条有条件的分支指令,它将根据 `icmp` 计算的条件跳转到 `block10` 或 `block19`。 - **条件判断与跳转**: 如果 `icmp` 结果为真(即条件成立),则跳转到 `block10`。如果结果为假(即条件不成立),则跳转到 `block19`。 - **插入位置**: 这条指令会被插入到 `entryBlock` 基本块的末尾。 生成的LLVM IR代码可能类似于: ```llvm br i1 %icmp, label %block10, label %block19 ``` - `br` 表示分支指令。 - `i1 %icmp` 表示条件值,`i1` 是1位的布尔值类型,`%icmp` 是条件值。 - `label %block10` 是条件为真时跳转的目标基本块。 - `label %block19` 是条件为假时跳转的目标基本块。 ret --- 在LLVM中,`ReturnInst` 是用于表示函数返回操作的指令。`ReturnInst` 是一个没有额外数据成员的类(即无data域),它主要通过继承自 `Instruction` 类来实现功能。`ReturnInst` 可以表示带有返回值的返回操作(例如从函数返回一个整数)或不带返回值的返回操作(返回 `void` 类型)。 ### 1. `ReturnInst` 的创建方法 `ReturnInst` 提供了一些静态方法 `Create`,用于创建返回指令。具体的创建方法如下: ```cpp static ReturnInst* Create(LLVMContext &C, Value *retVal = nullptr, Instruction *InsertBefore = nullptr) { return new(!!retVal) ReturnInst(C, retVal, InsertBefore); } static ReturnInst* Create(LLVMContext &C, Value *retVal, BasicBlock *InsertAtEnd) { return new(!!retVal) ReturnInst(C, retVal, InsertAtEnd); } static ReturnInst* Create(LLVMContext &C, BasicBlock *InsertAtEnd) { return new(0) ReturnInst(C, InsertAtEnd); } ``` - **`LLVMContext &C`**: LLVM上下文对象,管理LLVM中的全局数据。 - \**`Value* retVal`**: 可选参数,表示要返回的值。如果返回`void`,则这个值为`nullptr`。 - \**`Instruction* InsertBefore`\*\*: 可选参数,指示将返回指令插入到某条现有指令之前。 - \**`BasicBlock* InsertAtEnd`\*\*: 可选参数,指示将返回指令插入到某个基本块的末尾。 ### 2. 代码示例解析 ```cpp ReturnInst::Create(context, ld20, block15); ``` - **`context`**: 这是LLVM的上下文对象(`LLVMContext`),用于管理LLVM中的全局数据。 - **`ld20`**: 这是一个`Value*`类型的指针,表示要返回的值。在这个例子中,`ld20` 可能是一个加载指令(`LoadInst`)的结果,表示从某个内存位置加载的值。 - **`block15`**: 这是一个指向 `BasicBlock` 的指针,表示将返回指令插入到 `block15` 基本块的末尾。 ### 3. 解释 这段代码的作用是创建一条返回指令,它将 `ld20` 作为返回值,并将这条返回指令插入到 `block15` 基本块的末尾。 - **返回值**: 如果 `ld20` 表示一个整数值(假设是一个 `i32` 类型的值),那么这条返回指令将返回这个整数值。 - **插入位置**: 返回指令会被插入到 `block15` 基本块的末尾。 生成的LLVM IR代码可能类似于: ```llvm ret i32 %ld20 ``` - `ret i32 %ld20` 表示返回一个32位整数,`%ld20` 是返回的值。 如果没有返回值(即返回 `void` 类型),代码会是: ```cpp ReturnInst::Create(context, block15); ``` 生成的LLVM IR代码将类似于: ```llvm ret void ``` call ---- 在LLVM中,`CallInst` 是用来表示函数调用指令的类。它继承自 `CallBase`,而 `CallBase` 本身继承自 `Instruction`。`CallInst` 主要用于表示调用函数的操作,并且可以选择性地传递参数。由于函数调用在程序中的重要性,`CallInst` 提供了丰富的构造函数来适应不同的使用场景。 ### 1. `CallInst` 的内部结构 `CallInst` 继承自 `CallBase`,而 `CallBase` 具有自己的数据成员。这些数据成员包括: - **`CalledOperandOpEndIdx`**: 这是一个静态成员,通常用于管理操作数的索引。 - **`Attrs`**: 它是存储调用属性(如参数属性)的数据结构。 - **`FTy`**: 指向函数类型 (`FunctionType`) 的指针,表示被调用函数的类型。 这些成员帮助管理与函数调用相关的元数据、参数和操作数。 ### 2. `CallInst` 的创建方法 你提供的代码片段展示了LLVM中的`CallInst`类的多个静态工厂方法的声明。`CallInst`是LLVM IR(Intermediate Representation)中的一种指令类型,用于表示函数调用。这个类有许多重载的`Create`方法,用于创建`CallInst`对象。重载方法的存在使得在不同的上下文和需求下,可以灵活地创建函数调用指令。 ### 重载方法的分类与解释 这些重载方法大致可以分为几类,主要根据参数的不同来进行分类。下面是对每一类的解释: #### 1. **基本创建方法** - 方法签名: ```cpp static CallInst *Create(FunctionType *Ty, Value *F, const Twine &NameStr = "", Instruction *InsertBefore = nullptr); ``` - 作用: - 这是最基本的创建方法,用于创建一个简单的函数调用指令。 - 参数`Ty`表示函数的类型,`F`是实际的函数(或函数指针),`NameStr`是可选的名称字符串,`InsertBefore`是可选的参数,用于指定将指令插入到哪条指令之前。 - 用例: - 适用于不需要传递参数的函数调用场景,或者函数没有参数。 #### 2. **带参数的创建方法** - 方法签名: ```cpp static CallInst *Create(FunctionType *Ty, Value *Func, ArrayRef Args, const Twine &NameStr, Instruction *InsertBefore = nullptr); ``` - 作用: - 这个方法用于创建带有参数的函数调用指令。 - 参数`Args`是`Value`的数组,表示调用函数时传递的参数。 - 用例: - 适用于函数有参数的场景。 #### 3. **带参数和操作数包的创建方法** - 方法签名: ```cpp static CallInst *Create(FunctionType *Ty, Value *Func, ArrayRef Args, ArrayRef Bundles = None, const Twine &NameStr = "", Instruction *InsertBefore = nullptr); ``` - 作用: - 这个方法不仅可以传递参数,还可以传递“操作数包”(`OperandBundleDef`),这些包可以包含额外的元数据或附加信息。 - 用例: - 适用于需要传递额外元数据或操作数包的高级场景。 #### 4. **插入到基本块末尾的创建方法** - 方法签名: ```cpp static CallInst *Create(FunctionType *Ty, Value *F, const Twine &NameStr, BasicBlock *InsertAtEnd); ``` - 作用: - 这个方法用于创建一个调用指令,并将其插入到指定基本块的末尾。 - 参数`InsertAtEnd`是一个`BasicBlock`,表示要插入的基本块。 - 用例: - 适用于在基本块末尾插入指令的场景。 #### 5. **使用`FunctionCallee`类型的创建方法** - 方法签名: ```cpp static CallInst *Create(FunctionCallee Func, const Twine &NameStr = "", Instruction *InsertBefore = nullptr); ``` - 作用: - `FunctionCallee`是LLVM中的一个便利类型,封装了函数类型和函数的指针,简化了函数调用指令的创建。 - 用例: - 适用于使用`FunctionCallee`类型的场景,降低手动获取函数类型的复杂度。 #### 6. **带操作数包和替换操作数包的创建方法** - 方法签名: ```cpp static CallInst *Create(CallInst *CI, ArrayRef Bundles, Instruction *InsertPt = nullptr); static CallInst *CreateWithReplacedBundle(CallInst *CI, OperandBundleDef Bundle, Instruction *InsertPt = nullptr); ``` - 作用: - 这些方法用于创建一个新的调用指令,基于已有的调用指令`CI`,并添加或替换操作数包。 - 用例: - 适用于需要复制现有指令并修改其操作数包的场景。 #### 实例 ```c Function* myAddFunc = module->getFunction("myadd"); Value *arg[] = {old_ope->getOperand(0), old_ope->getOperand(1)}; CallInst *myaddCall = CallInst::Create(myAddFunc, arg, ""); ``` 1. 从当前 LLVM 模块中获取名为 `"myadd"` 的函数指针。 2. 通过从某个现有操作(`old_ope`)中提取两个操作数,作为调用 `"myadd"` 函数的参数。 3. 创建一个新的函数调用指令,调用 `"myadd"` 函数,并传递提取的两个参数。 最后,`myaddCall` 是创建的调用指令对象,它可以在 LLVM IR 中被插入到合适的位置,以便在生成的代码中执行这个函数调用。 参考 == [https://bbs.kanxue.com/thread-274259.htm#msg\_header\_h2\_1](https://bbs.kanxue.com/thread-274259.htm#msg_header_h2_1) <http://www.blackbird.wang/2022/08/30/LLVM-PASS%E7%B1%BBpwn%E9%A2%98%E6%80%BB%E7%BB%93/> [LLVM基础知识](https://blog.csdn.net/qq_45323960/article/details/132599010?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171928250416800178515048%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=171928250416800178515048&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-132599010-null-null.nonecase&utm_term=LLVM&spm=1018.2226.3001.4450) [https://buaa-se-compiling.github.io/miniSysY-tutorial/pre/design\_hints.html](https://buaa-se-compiling.github.io/miniSysY-tutorial/pre/design_hints.html) [https://blog.csdn.net/qq\_45323960/article/details/129691707?ops\_request\_misc=%257B%2522request%255Fid%2522%253A%2522171928250416800178515048%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request\_id=171928250416800178515048&biz\_id=0&utm\_medium=distribute.pc\_search\_result.none-task-blog-2~blog~first\_rank\_ecpm\_v1~rank\_v31\_ecpm-2-129691707-null-null.nonecase&utm\_term=LLVM&spm=1018.2226.3001.4450](https://blog.csdn.net/qq_45323960/article/details/129691707?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171928250416800178515048%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=171928250416800178515048&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-2-129691707-null-null.nonecase&utm_term=LLVM&spm=1018.2226.3001.4450) [https://xz.aliyun.com/t/11762?time\_\_1311=mqmx0DBDcD2DuiCD%2FQbKBKFxr73BPhD&alichlgref=https%3A%2F%2Fwww.google.com.hk%2F](https://xz.aliyun.com/t/11762?time__1311=mqmx0DBDcD2DuiCD/QbKBKFxr73BPhD&alichlgref=https://www.google.com.hk/)
发表于 2024-11-08 09:00:01
阅读 ( 9782 )
分类:
其他
0 推荐
收藏
0 条评论
麦当当
4 篇文章
×
温馨提示
您当前没有「奇安信攻防社区」的账号,注册后可获取更多的使用权限。
×
温馨提示
您当前没有「奇安信攻防社区」的账号,注册后可获取更多的使用权限。
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!