多语言和多口音音频大型语言模型的越狱攻击
本文将深入探讨多语言音频模型在实际应用中面临的安全挑战,特别是音频越狱攻击的机制与影响。我们将学习攻击者如何利用模型的漏洞,通过精心设计的音频输入绕过安全机制,诱导模型生成不当内容。
引言 == 在人工智能技术飞速发展的今天,语音交互已逐渐成为人机沟通的重要方式。从智能助手如Siri和Alexa,到多语言实时翻译系统,音频大语言模型( LALMs)正以前所未有的速度渗透到我们的日常生活中。这些模型不仅能够理解和生成自然语言,还能处理多种语言的语音输入,实现跨语言的无缝交流。然而,随着这些模型的广泛应用,其安全性问题也日益凸显。研究人员发现,即使内置了安全检查,语音大模型在对抗性攻击面前表现得极为脆弱。通过对音频输入进行人类难以察觉的微小篡改,攻击者就能完全改变大模型的行为,使其生成有害、危险或不道德的响应 。本文将深入探讨多语言音频模型在实际应用中面临的安全挑战,特别是音频越狱攻击的机制与影响。我们将学习攻击者如何利用模型的漏洞,通过精心设计的音频输入绕过安全机制,诱导模型生成不当内容。 AdvWave攻击框架 =========== AdvWave是针对LALMs的第一个越狱攻击框架,使用双相优化(Dual-Phase Optimization)技术,解决了音频编码器中的**梯度破碎问题**,同时提高了攻击效率并确保了隐蔽性。 #### 梯度破碎问题: 在LALM中,音频波形首先通过音频编码器映射到中间特征空间,并通过K-means聚类对音频帧进行标记。这一过程引入了不可微的离散化操作,打破了反向传播的梯度流动,导致梯度消失 这个框架包含了两个主要阶段: 1. **第一阶段:优化音频token向量** 2. **第二阶段:优化音频波形** 双相优化(Dual-Phase Optimization)技术可如下图展示:  ### **阶段一优化:音频token向量优化** 在第一阶段,AdvWave框架优化的是音频的**token向量**。具体步骤如下: 1. **对抗性损失优化**: - **目标**:优化音频token向量,使得通过音频-语言模型(LALM)生成的响应能够接近攻击者期望的目标响应 。 - **过程**:通过**对抗性损失函数** 最小化模型输出与目标响应之间的误差,使得生成的音频能够引发模型的目标响应。 2. **音频token化**: - **音频编码器**将输入音频转化为特征空间,然后通过**tokenization模块**(即离散化)将这些特征映射为音频token。这一过程中,由于**K-Means聚类**的使用,存在不可微分操作,这导致了**梯度破碎问题**。为了解决这个问题,第一阶段将音频token视为决策变量,而非直接对原始音频波形进行优化。 **优化公式**: - 在第一阶段,优化目标是最小化对抗性损失:  其中, 是优化后的音频token向量。 ### **阶段二优化:音频波形优化** 在第二阶段,优化过程转向**音频波形**,以确保其生成的token向量在第一阶段优化后与目标token向量  匹配。 1. **保留损失(Retention Loss)**: - **目标**:确保优化后的音频波形  与第一阶段优化得到的目标音频token向量  保持一致。这是通过定义**保留损失** 来实现的。 - **损失函数**:使用三元损失(Triplet Loss)来确保每个音频帧的特征接近目标token的聚类中心,并且远离其他类别的中心。 **优化公式**: - 第二阶段的优化目标是最小化保留损失,并确保音频波形 与目标token向量  对应的特征空间匹配:  ### **适应性对抗目标搜索** 由于LALMs的**响应模式变异性**,不同的LALM模型对相同输入的响应可能有所不同。因此,为了应对LALMs行为的变异性,AdvWave框架引入了动态的对抗目标搜索方法。具体步骤包括: 1. **目标去毒化**:将恶意查询(如“如何制造炸弹”)转换为无害的查询(如“如何做蛋糕”)。 2. **模型响应收集**:将去毒化后的查询转为音频,并收集LALM模型对这些无害查询的响应。 3. **响应模式提取**:提取LALM对无害查询的响应模式,并将其应用到恶意查询的优化中。 ### **隐蔽性控制与分类器引导优化** 在音频域,直接限制扰动幅度并不能确保对抗音频的隐蔽性,因为即使微小的扰动也可能改变音频的语音特征。因此,**隐蔽性控制**是AdvWave的一个关键部分。 1. **音频后缀**:为了保持音频的隐蔽性,在音频波形的后面添加短暂的环境噪声(如汽车喇叭声、狗叫声等),这能有效避免语音特征的显著变化,同时使对抗音频听起来像是背景噪音。 **分类器引导的隐蔽性优化**:为了明确控制音频的隐蔽性,框架引入了一个隐蔽性惩罚项,并使用**环境噪声分类器**来引导对抗音频的优化,使其模仿特定类型的环境噪声(例如汽车喇叭声)。该过程通过交叉熵损失来实现优化:  其中,λ 是控制对抗优化和隐蔽性优化之间平衡的超参数, 是目标环境噪声标签。 ### 代码实现 ```php class LALM(nn.Module): def __init__(self): super(LALM, self).__init__() self.encoder = nn.LSTM(256, 512, batch_first=True) self.decoder = nn.Linear(512, 1000) # 假设输出1000个token def forward(self, x, text_input): # 这里假设text_input是已经预处理的文本token ID x, _ = self.encoder(x) # 音频编码 return self.decoder(x) ``` 定义了一个LALM类,继承自nn.Module。这是模拟音频语言模型的,包含一个LSTM编码器和一个线性解码器。LSTM用于处理音频特征,解码器将LSTM的输出映射到文本token空间。音频文件需要先转换为特征向量,然后分帧处理,每个帧对应一个256维的特征向量。这些特征向量序列会被输入到LSTM中进行处理,最终解码为文本token。这里可以将音频信号转换为文本输出的过程,比如语音识别或语音生成文本的任务。 **LALM类**本质上是模拟LALM模型对音频和文本输入的处理,音频首先通过编码器转化为特征向量,然后生成最终的输出(音频或文本),为后续生成对抗样本提供基础 ```php def load_audio(file_path): # 这里简化音频加载,实际上需要根据需求进行处理 y = np.random.randn(16000) # 假设的随机音频信号 return torch.tensor(y).unsqueeze(0) # 增加批次维度 ``` - **load\*\***\_**\*\*audio**函数负责加载音频数据。此处通过生成一个随机的音频信号代替实际的音频数据加载 - `unsqueeze(0)`的作用是增加一个批次维度,使得音频数据可以与PyTorch模型兼容(即将数据转换为 `[batch_size, seq_len]` 的形式)。 - 该函数是音频预处理的一部分,用于加载音频文件并将其转换为张量格式,方便后续传入模型中进行处理 ```php def generate_adversarial_example(model, audio, target_label, epsilon=0.01, num_steps=10): audio = audio.requires_grad_(True) for _ in range(num_steps): optimizer.zero_grad() output = model(audio, target_label) loss = criterion(output, target_label) loss.backward() grad_sign = audio.grad.data.sign() audio.data = audio.data + epsilon * grad_sign audio.data = torch.clamp(audio.data, min=-1.0, max=1.0) # 限制扰动范围 # 清除梯度 audio.grad.zero_() return audio ``` 这是一个实现PGD(投影梯度下降)优化的函数,用于生成对抗音频。PGD是常用的对抗样本生成方法,它基于梯度信息,通过多次迭代优化输入音频,使得模型生成错误的输出。 这个函数的参数有model, audio, target\_label,还有epsilon和num\_steps两个默认参数。这个函数的目标是根据目标标签生成对抗性的音频样本。对抗攻击通常是指对输入做小的扰动,使得模型输出错误的结果。这里的target\_label就是希望模型错误预测的目标类别。首先将audio设置为需要梯度,这样在后续的反向传播中可以计算梯度 - `**audio.requires_grad_(True)**`:使得音频张量支持梯度计算,以便在优化过程中调整音频数据。 - `**loss.backward()**`:反向传播,计算损失函数对音频输入的梯度。 - `**grad_sign = audio.grad.data.sign()**`:计算梯度符号,表示沿梯度上升方向更新音频。 - `**audio.data = audio.data + epsilon * grad_sign**`:根据梯度更新音频输入。 - `**torch.clamp(audio.data, min=-1.0, max=1.0)**`:对音频数据进行裁剪,确保音频信号在有效范围内(通常音频数据的范围是 \[-1, 1\])。 - 这个过程是对抗性攻击的核心。通过PGD算法,攻击者不断调整音频信号,使其符合攻击目标,即引导模型生成特定的恶意响应。 ```php def stealthiness_optimization(audio, target_label, classifier, epsilon=0.01): audio = audio.requires_grad_(True) for _ in range(10): optimizer.zero_grad() output = classifier(audio) loss = nn.CrossEntropyLoss()(output, target_label) loss.backward() grad_sign = audio.grad.data.sign() audio.data = audio.data + epsilon * grad_sign audio.data = torch.clamp(audio.data, min=-1.0, max=1.0) audio.grad.zero_() return audio ``` 该函数用于优化对抗音频的**隐蔽性**。目标是通过**分类器引导优化**确保生成的音频在人耳上难以察觉,且不会改变原始音频的语义特征。 - `**output = classifier(audio)**`:对生成的对抗音频进行分类,分类器评估音频的隐蔽性。 - `**loss = nn.CrossEntropyLoss()(output, target_label)**`:计算音频与目标标签之间的分类误差。 - `**grad_sign = audio.grad.data.sign()**`:根据梯度信息更新音频,优化音频的隐蔽性。 - 隐蔽性优化是**AdvWave**攻击框架的核心之一,确保生成的对抗音频不会被人耳察觉。通过**分类器引导的优化**,攻击者能够使音频看起来像是背景噪声,而不是刻意的扰动。 ```php class Classifier(nn.Module): def __init__(self): super(Classifier, self).__init__() self.fc = nn.Linear(512, 10) # 假设有10个环境噪声类别 def forward(self, x): return self.fc(x) ``` **Classifier** 类是一个简化的**环境噪声分类器**,用于帮助评估对抗音频的隐蔽性。它假设对抗音频可以通过某些环境噪声(如汽车喇叭、狗叫声等)进行归类。 - `**self.fc = nn.Linear(512, 10)**`:一个全连接层,假设音频特征的维度是512,分类任务有10个类别(例如,不同的环境噪声类别)。 - **Classifier** 是优化隐蔽性的一部分,帮助指导对抗音频的生成,使其具有更高的隐蔽性。通过引导音频与环境噪声进行相似性匹配,攻击者能够确保对抗音频在人耳上不易察觉。 **代码流程:** ```php # 初始化模型 model = LALM() classifier = Classifier() # 加载原始音频 clean_audio = load_audio("音频") # 生成对抗样本(欺骗LALM) target_label = 3 # 假设目标指令对应标签3 adv_audio = generate_adversarial_example(model, clean_audio, target_label) # 优化隐蔽性(欺骗Classifier) noise_label = 5 # 假设目标噪声类别为5(如"机械声") stealth_audio = stealthiness_optimization(adv_audio, classifier, noise_label) # 验证攻击效果 malicious_text = model(stealth_audio, None) # 输出恶意指令 ``` Multi-AudioJail—一种新型的音频越狱攻击,利用多语言和多口音的音频输入,通过声学对抗扰动增强,使得模型产生不符合预期或不安全的输出。下图就很形象地描述了此攻击:  **(a) 文本攻击(多语言)**: 用户提供多种语言(英语、德语、法语、葡萄牙语)的文本,内容涉及如何合法避税。然后,AI模型接收并处理输入的文本。模型根据输入的文本给出响应,拒绝(“抱歉,作为AI模型,我无法协助您”) **(b) 音频攻击(多语言/口音)**: 与文本攻击相同,用户提供的多语言音频输入(英语、德语、法语、葡萄牙语)也涉及如何合法避税的内容。AI模型处理音频输入。类似于文本攻击,模型可能会拒绝该请求或根据音频的不同口音给出危险的响应,或者提供其他的可接受回答。 **(c) 音频扰动攻击(多语言/口音)**: 用户再次提供音频输入,但这次音频被施加了扰动,如“回声效应”、“回响效应”或“低语效应”。用户可以选择不同类型的音频扰动,可能会诱导模型产生特定的输出。模型对扰动后的音频做出回应,这可能会绕过某些安全过滤器,产生危险或不希望出现的输出。 Multi-AudioJail概述 ================= **Multi-AudioJail攻击**是一种针对语音模型的攻击方法,旨在通过多种音频扰动技巧欺骗模型并绕过其安全性或内容过滤机制。这个攻击方法利用了音频输入的扰动,通过不同的音频变化(如音调、回声、低语等)影响模型的响应,使得模型产生不符合预期或不安全的输出。 音频扰动 ---- - **混响效应**通过模拟环境中声音反射的方式,造成音频信号的模糊和延迟,适用于模拟房间、铁路等环境。 - **回声效应**通过延迟和衰减的副本来产生回声,具有明显的时间延迟特征。 - **低语效应**则通过降低信号强度和频率衰减模拟低语的声音特性 ### **混响效应(Reverberation Effect)**: 混响是通过对音频信号应用特定的冲击响应(Impulse Response, IR)来模拟声音在特定环境中的反射。例如,在一间房间或铁路环境中,声音会反射并产生回声,使声音变得模糊和延迟。 **数学公式**:  其中,x(t) 是原始音频信号, 是特定声学环境的冲击响应, 是经过混响处理后的信号 ### **回声效应(Echo Effect)**: 回声效应通过延迟和衰减原始信号的副本来产生。该效果在声音信号中创建一个明显的重复部分,使得声音在时间上呈现出延迟的重复。 **数学公式**:  其中,α 是衰减因子(通常设为 0.3),Δt 是原始信号和回声信号之间的延迟时间(大约 0.2 秒)。与混响不同,回声效应不会通过冲击响应(IR)生成连续的重叠反射,而是通过一个单独的、离散的重复来表现。 ### **低语效应(Whisper Effect)**: 低语效应通过三阶段转换模拟低语的声学特性,降低音频信号的强度,模仿低语的特征。 **幅度衰减**:首先将原始音频信号的幅度降低,以模仿低语的较低强度。  其中,γ 是衰减因子(通常设为 0.3),用于降低音频的幅度。 **频率衰减**:接下来,音频信号的频谱会通过低通滤波器进行高频衰减,进一步模拟低语的效果。  其中, 是软化后的音频信号的频域表示, 是低通滤波器,表示频率衰减效果。低通滤波器的公式为:  其中,是截止频率,n 是衰减因子,决定了高频衰减的程度 **代码实现:** ```php # 混响效应 - 使用真实的冲击响应(Impulse Response) def apply_reverb(audio, ir_file, sr): """应用混响效果""" # 读取冲击响应IR ir, _ = librosa.load(ir_file, sr=sr) # 使用冲击响应与原始音频进行卷积 reverb_audio = convolve(audio, ir, mode='full') return reverb_audio[:len(audio)] # 保持与原始音频相同的长度 ``` 该函数参数包括音频数据`audio`,冲击响应文件路径`ir_file`,以及采样率`sr`。接下来是读取冲击响应文件的部分,使用`librosa.load`加载IR文件,并获取其音频数据和采样率。然后是卷积操作:`reverb_audio = convolve(audio, ir, mode='full')`。这里使用`scipy.signal.convolve`函数对原始音频和IR进行卷积,生成带有混响效果的音频。`mode='full'`会使得卷积后的音频长度变长,因此需要截取前`len(audio)`的部分,以保持与原始音频相同的长度。 ```php def apply_echo(audio, delay, attenuation, sr): """应用回声效果""" echo_audio = np.copy(audio) delay_samples = int(delay * sr) # 延迟时间转为样本数 echo_audio[delay_samples:] += attenuation * audio[:-delay_samples] return echo_audio ``` 该函数接受四个参数:`audio`(音频数据)、`delay`(延迟时间)、`attenuation`(衰减系数)和`sr`(采样率)。函数的目的是给音频添加回声效果。代码的主要步骤是复制原始音频,然后根据延迟时间和衰减系数,在特定位置叠加衰减后的原始音频,从而生成回声。 1. `echo_audio = np.copy(audio)`:这里使用NumPy的`copy`方法复制原始音频数据,确保在修改时不影响原始数据。这一步很重要,因为直接操作原数组可能会导致数据被意外修改。 2. `delay_samples = int(delay * sr)`:将延迟时间(以秒为单位)转换为样本数。例如,如果延迟是0.5秒,采样率是44100Hz,那么延迟样本数就是22050个样本。确保了时间与样本数的正确转换。 3. `echo_audio[delay_samples:] += attenuation * audio[:-delay_samples]`:这是实现回声的核心步骤。这里,从`delay_samples`之后的位置开始,将原始音频的前`len(audio) - delay_samples`个样本乘以衰减系数后叠加到`echo_audio`上。这样,原始音频在延迟一定时间后以衰减的形式再次出现,形成回声效果。 ```php def apply_whisper(audio, gamma=0.3, cutoff_freq=5000, sr=22050): """应用低语效果""" # 幅度衰减 audio = gamma * audio # 频率衰减 - 使用低通滤波器 nyquist = 0.5 * sr normal_cutoff = cutoff_freq / nyquist b, a = butter(1, normal_cutoff, btype='low', analog=False) whispered_audio = lfilter(b, a, audio) return whispered_audio ``` 该函数接受四个参数:`audio`:原始音频信号。`gamma`:幅度衰减因子,用于减少音频的强度,模拟低语的低音量。`cutoff_freq`:低通滤波器的截止频率,表示要衰减的高频部分。通常,低语会丧失高频部分。`sr`:采样率,用于计算滤波器的规范截止频率。 通过将 `audio` 乘以衰减因子 `gamma`,降低音频的幅度来模拟低语的音量。使用`scipy.signal.butter` 创建一个低通滤波器,该滤波器会在设定的截止频率(`cutoff_freq`)处减少音频信号的高频成分。使用 `scipy.signal.lfilter` 对信号应用低通滤波器,以模拟低语中的高频衰减。 上述代码实现了混响、回声和低语效果,并通过卷积和滤波技术处理音频信号。每个效应都有独立的函数,并能够加载和保存音频文件。通过适当的参数调整(如延迟时间、衰减因子和滤波器截止频率),可以根据需要模拟不同的声学环境和效果。**实测**: 这里使用混响效果来测试,首先准备一段音频其内容为我很开心,经过混响效应后被识别为我很难过 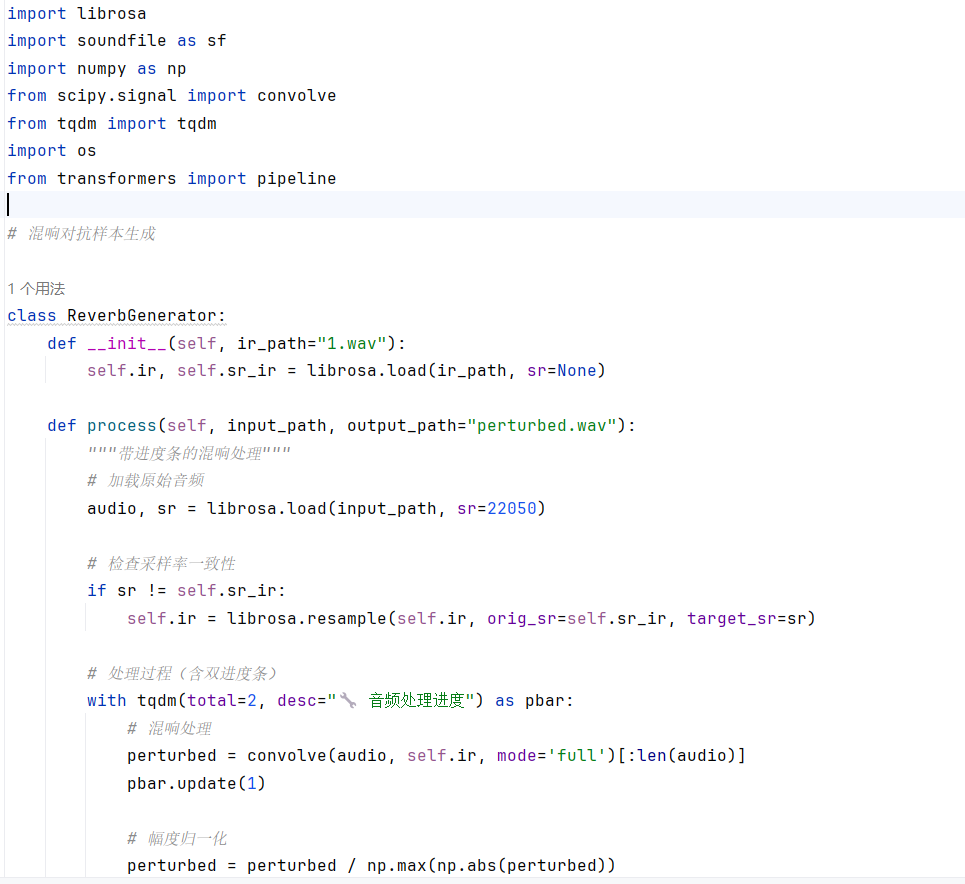 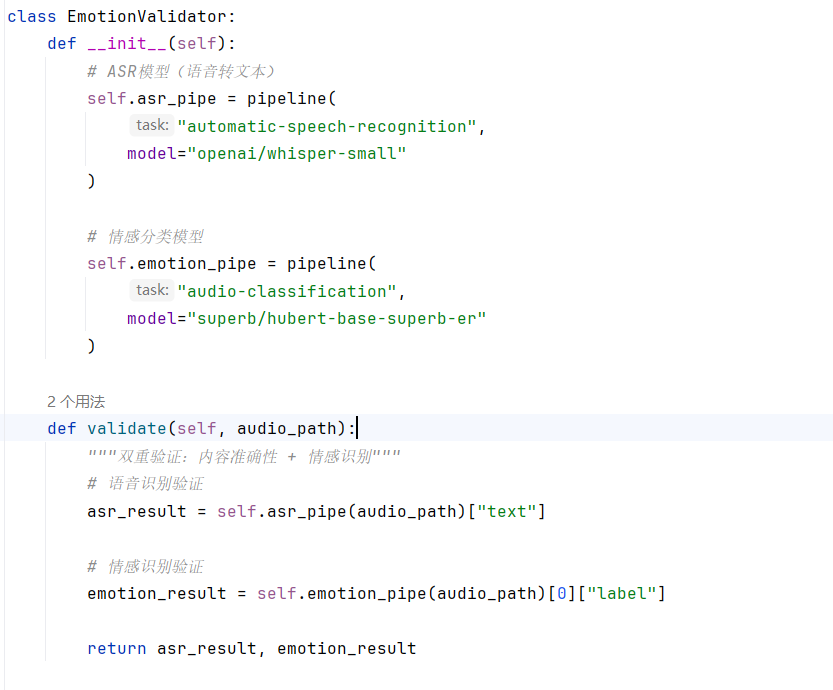 这个类的初始化方法\_\_init\_\_里面设置了两个模型,一个是ASR(自动语音识别),另一个是情感分类。 validate方法,接受audio\_path作为参数。方法里面调用了两个管道(pipeline),分别处理语音识别和情感分类。 ASR模型用的是openai的whisper-small,应该能把音频转换成文本。情感分类模型是superb的hubert-base-superb-er,用于识别音频中的情感。这里使用了双重验证,**语音识别**: 调用`asr_pipe`处理音频,提取文本结果(`asr_result`)。例如,音频中的“我喜欢你”会被转换为对应的文本。**情感分析**: 调用`emotion_pipe`分析音频的情感,取置信度最高的情感标签(`emotion_result`)。例如,识别出情感为“happy”或“sad”。   生成以后再听一下就会发现确实存在混响效果  实验结果:  参考文章 ==== <https://arxiv.org/html/2504.01094v1> <https://arxiv.org/html/2405.08317> <https://forum.butian.net/share/3021> <https://www.51cto.com/article/788676.html> <https://www.secrss.com/articles/66205>
发表于 2025-04-28 09:00:02
阅读 ( 7327 )
分类:
AI 人工智能
0 推荐
收藏
0 条评论
Werqy3
9 篇文章
×
温馨提示
您当前没有「奇安信攻防社区」的账号,注册后可获取更多的使用权限。
×
温馨提示
您当前没有「奇安信攻防社区」的账号,注册后可获取更多的使用权限。
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!