我用MCP开发了一个AI目录扫描分析工具
安全工具
渗透测试
本工具结合了当下的MCP协议中sse方案,给传统的目录扫描工具dirsearch对接上了AI大模型,并对扫描结果进行数据筛选及深度分析并输出漏洞报告。
一、工具介绍 ====== 本工具结合了当下的MCP协议中的sse方案(**为何不用stdio方案下文有讲**),给传统的目录扫描工具dirsearch对接上了AI大模型,并对扫描结果进行下一步分析,以及输出漏洞报告,未来还会进行拓展以及微调,实现漏洞扫描流程自动化,目前效果如下 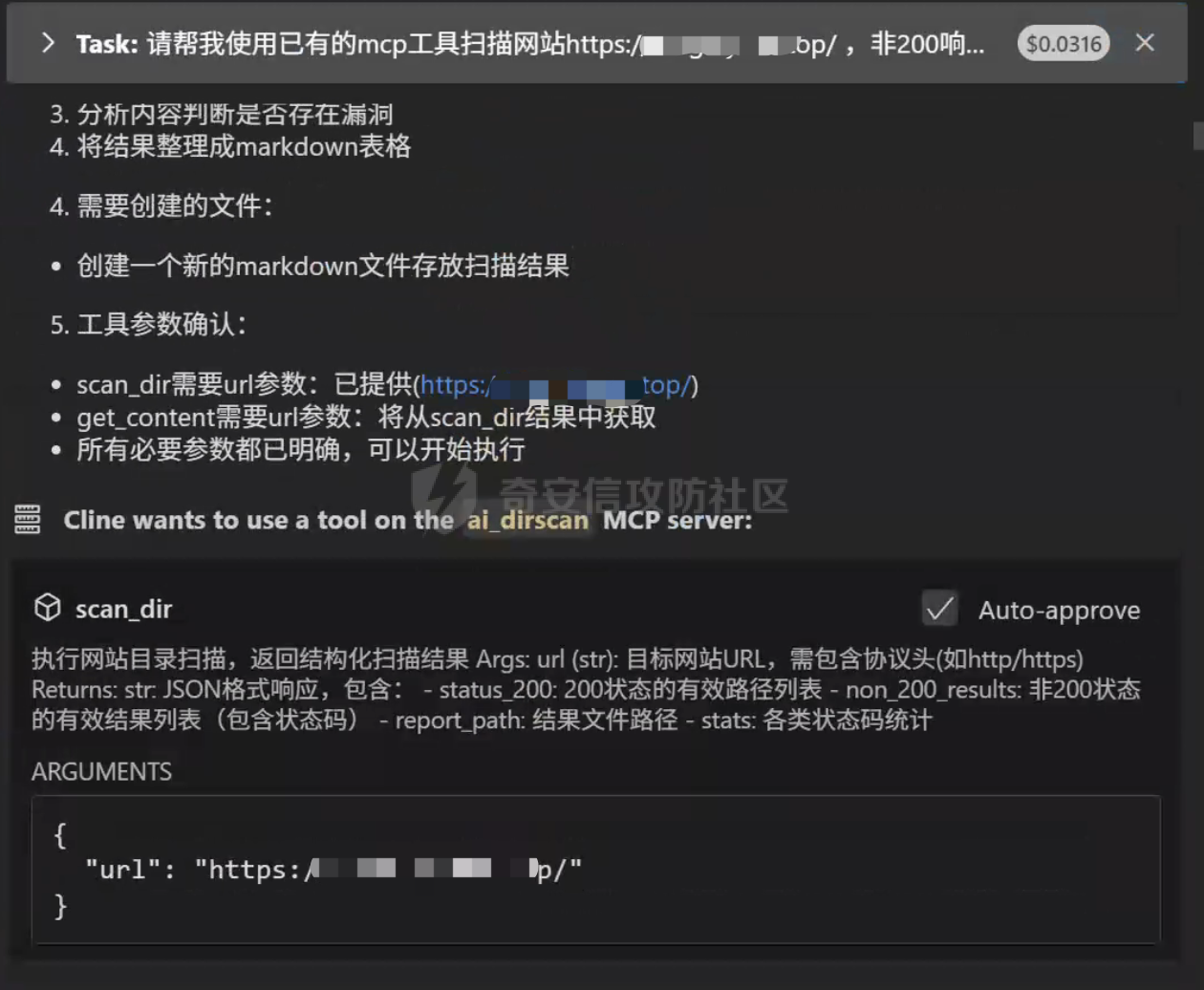 自动分析非200页面网页内容,可用于发现服务器版本泄露,框架类型版本泄露,网站绝对路径泄露等漏洞,并在分析完所有扫描得到的路径之后,会产出md格式漏洞报告(依赖于Cline) > 为节省LLM的api tokens,对扫描结果进行了数据筛选工作,以 状态码+返回包大小 作为判断标识,同样的组合仅保留分析一组  项目地址: > [ai\_dirscan](https://github.com/Elitewa/ai_dirscan) 二、MCP服务端编写 ========== 2.1 环境初始化 --------- 为了使我们的mcp服务不和主环境冲突,这里先设置下uv虚拟环境 ```sh uv init ai_dirscan cd ai_dirscan uv venv ```  然后我们将 dirsearch 工具的目录复制到当前工作目录中,dirsearch源码推荐GitHub下载 > [dirsearch下载链接](https://github.com/maurosoria/dirsearch) 此时我们的项目目录结构应该如下:  然后安装MCP和dirsearch所需依赖,命令如下: ```sh source .venv/bin/activate #win环境下为 .venv\Scripts\activate.bat uv add "mcp[cli]" uv add requests deactivate cd dirsearch pip install -r requirements.txt pip install setuptools ``` 我们测试下dirsearch在当前环境中是否可用,命令如下 ```sh python3 dirsearch.py -u https://src.sjtu.edu.cn/ ``` 出现如图所示界面及代表虚拟环境依赖配置成功  2.2 模块导入及服务注册 ------------- 我们用vs code打开刚才创建的虚拟环境目录ai\_dirscan 可以看到有默认生成的main.py  首先导入一些必要的库,其中`FastMCP`模块即提供本地的mcp服务,代码如下: ```python import json import subprocess from datetime import datetime from pathlib import Path from mcp.server.fastmcp import FastMCP # 初始化 MCP 服务 mcp = FastMCP("ai_dirscan",port=8000) //注册mcp服务名为ai_dirscan,sse服务端口设置为 默认8000 ``` 2.3 扫描流程处理 ---------- ### 2.3.1 总体交互 然后当前工具与ai的数据交互方式如下,以下均为作者本人的想法,如果有更好的解决方案,欢迎提出 **数据交互**(file): > 由于大模型有上下文token字数限制,且过多无用的扫描数据也存在**浪费api的token**及**生成过慢**的危害,所以我先将原始dirsearch扫描结果中输出到文件,然后经过筛选去重返回给LLM处理 > > 为什么要输出到文件中,再中转给LLM呢? > > 因为LLM常常是不可信的,我们可以通过准确的结果数据与LLM输出的结果进行对比,从而进行微调训练,逐渐矫准 数据交互部分对应代码如下: ```python # 配置存储路径 SCAN_RESULT_DIR = Path("scan_results") SCAN_RESULT_DIR.mkdir(exist_ok=True) …… # 生成结果文件路径 timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") output_file = SCAN_RESULT_DIR / f"scan_{timestamp}.json" …… # 加载原始扫描结果 with open(output_file, "r", encoding="utf-8") as f: scan_data = json.load(f) #……处理逻辑 ``` **传输交互**(sse): > 因为我们知道常规目录扫描作业很多都是超过30s的,经过作者查阅资料发现MCP的stdio协议中,工具超时调用时间是硬编码在协议中的,默认为30s且无法更改,而由于sse协议涉及到与服务器的http网络交互,其中的超时时间是可以更改的,但目前支持更改该时间的客户端只有新版的Cline插件,除此之外唯有手搓一个客户端才能解决 传输交互部分对应代码如下: ```python if __name__ == "__main__": mcp.run(transport='sse') ``` ### 2.3.2 工具注解词 MCP客户端在调用tool时,会查阅函数下以**""" """**注解的语句,从而进行判断调用,该语句尽量写的简单明确且格式化,注明返回格式 我们注册一个@mcp.tool(),以将函数暴露ai识别调用,代码如下: ```python @mcp.tool() def scan_dir(url: str) -> str: """ 执行网站目录扫描,返回结构化扫描结果 Args: url (str): 目标网站URL,需包含协议头(如http/https) Returns: str: JSON格式响应,包含: - status_200: 200状态的有效路径列表 - non_200_results: 非200状态的有效结果列表(包含状态码) - report_path: 结果文件路径 - stats: 各类状态码统计 """ ``` ### 2.3.3 工具调用及数据筛选 我们通过`subprocess`子进程模块对项目中的 dirsearch工具 进行调用,由于dirsearch工具本身就具有**定向输出文件**(-o),所以我们可以直接在dirsearch中实现结果输出 > 对于不带此类命令的工具,我们可能需要麻烦一点,例如获取subprocess的执行结果,然后针对此工具的结果返回格式,编写出对应的函数解析过滤然后写出文件 该部分功能代码如下: ```python # 构建扫描命令 base_cmd = [ "python3", "./dirsearch/dirsearch.py", "-u", url, "-o", str(output_file), "--format=json", "-q", "--no-color", ] try: # 执行扫描命令[8](@ref) subprocess.run( base_cmd, check=True, capture_output=True, timeout=300, text=True ) ``` 为节省tokens,我们对结果目录进行了数据筛选工作,以 **状态码+返回包大小** 作为判断标识,同样的组合仅保留分析一组,代码如下 ```python # 结果分类处理 for entry in scan_data.get("results", []): status = entry["status"] url_path = entry["url"] content_length = entry["content-length"] # 状态码统计 status_counter[status] += 1 # 生成唯一标识符防止重复 entry_key = f"{status}|{content_length}" if entry_key in unique_tracker: continue unique_tracker.add(entry_key) # 分类存储结果 if status == 200: status_200.append(url_path) elif content_length != 0: non_200_results.append({ "url": url_path, "status": status, "content_length": content_length }) ``` ### 2.3.4 结果返回及报错处理 接下来便是结果返回,因为LLM更善于解析格式明确的语句,这里我们以固定的json格式返回 并且为了方便LLM进行下一步处理,我们将扫描得到的目录,分为了 **200响应码** 和 **非200响应码**,为了节省mcp调用时间,以及节约tokens,目前工具只会对非200响应码进行**深度分析**,得到由网站报错导致的`服务器版本泄露`,`绝对路径泄露`等漏洞。 该工具将会返回**网站目录**、**扫描结果保存目录**、**统计信息** 代码如下: ```python # 生成最终响应 response = { "status": 200, "data": { "status_200": status_200, "non_200_results": non_200_results, "report_path": str(output_file), "stats": stats }, "message": "扫描完成,结果已分类" } ``` 为了更好的获取数据,调试程序和LLM,我加入了报错处理功能,可以让ai返回具体的报错信息,以供我们进行修复,代码如下: ```python except json.JSONDecodeError as e: response = {"status": 500, "message": f"结果解析失败: {str(e)}"} except subprocess.TimeoutExpired: response = {"status": 408, "message": "扫描超时"} except Exception as e: response = {"status": 500, "message": f"扫描失败: {str(e)}"} ``` 最后便是运行mcp服务的代码,目前大部分mcp客户端支持的对接方式有两种:**stdio(本地)**,**sse(服务器)**,因为我们项目是在本地开发的并没有上传到服务器,故选择 stdio,代码如下: ```python if __name__ == "__main__": mcp.run(transport='stdio') ``` 2.4 深度分析处理 ---------- 为了对非200响应码进行**深度分析**,得到由网站报错导致的`服务器版本泄露`,`绝对路径泄露`等漏洞,我们需编写MCP工具`get_content`,利用requests模块获取网页内容,从而进行分析,代码如下: ```python @mcp.tool() def get_content(url: str) -> str: """ 获取非200响应界面的网页内容 :param url: 需要检测的网页地址 :return: 返回页面的完整内容(若目标页面返回非200状态码) """ try: response = requests.get( url, headers={"User-Agent": "Mozilla/5.0"}, timeout=5 ) if response.status_code != 200: return response.text return f"200响应页面,无需进行深度分析" except requests.exceptions.RequestException as e: return f"请求异常:{str(e)}" ``` 2.5 完整代码 -------- 服务端完整代码如下 ```python import json import subprocess from collections import defaultdict import requests from datetime import datetime from pathlib import Path from mcp.server.fastmcp import FastMCP # 初始化 MCP 服务 mcp = FastMCP("ai_dirscan",port=8000) # 配置存储路径 SCAN_RESULT_DIR = Path("scan_results") SCAN_RESULT_DIR.mkdir(exist_ok=True) @mcp.tool() def scan_dir(url: str) -> str: """ 执行网站目录扫描,返回结构化扫描结果 Args: url (str): 目标网站URL,需包含协议头(如http/https) Returns: str: JSON格式响应,包含: - status_200: 200状态的有效路径列表 - non_200_results: 非200状态的有效结果列表(包含状态码) - report_path: 结果文件路径 - stats: 各类状态码统计 """ # 生成结果文件路径 timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") output_file = SCAN_RESULT_DIR / f"scan_{timestamp}.json" # 构建扫描命令 base_cmd = [ "python3", "./dirsearch/dirsearch.py", "-u", url, "-o", str(output_file), "--format=json", "-q", "--no-color", ] response = {"status": 500, "message": "初始化失败"} try: # 执行目录扫描 subprocess.run( base_cmd, check=True, capture_output=True, timeout=300, text=True ) # 加载原始扫描结果 with open(output_file, "r", encoding="utf-8") as f: scan_data = json.load(f) # 初始化数据结构 status_200 = [] non_200_results = [] status_counter = defaultdict(int) unique_tracker = set() # 结果分类处理 for entry in scan_data.get("results", []): status = entry["status"] url_path = entry["url"] content_length = entry["content-length"] # 状态码统计 status_counter[status] += 1 # 生成唯一标识符防止重复 entry_key = f"{status}|{content_length}" if entry_key in unique_tracker: continue unique_tracker.add(entry_key) # 分类存储结果 if status == 200: status_200.append(url_path) elif content_length != 0: non_200_results.append({ "url": url_path, "status": status, "content_length": content_length }) # 构建统计信息 stats = { "total_200": len(status_200), "total_non_200": len(non_200_results), "status_distribution": dict(status_counter) } # 生成最终响应 response = { "status": 200, "data": { "status_200": status_200, "non_200_results": non_200_results, "report_path": str(output_file), "stats": stats }, "message": "扫描完成,结果已分类" } except json.JSONDecodeError as e: response = {"status": 500, "message": f"结果解析失败: {str(e)}"} except subprocess.TimeoutExpired: response = {"status": 408, "message": "扫描超时"} except Exception as e: response = {"status": 500, "message": f"扫描失败: {str(e)}"} return json.dumps(response, ensure_ascii=False, indent=2) @mcp.tool() def get_content(url: str) -> str: """ 获取非200响应界面的网页内容 :param url: 需要检测的网页地址 :return: 返回页面的完整内容(若目标页面返回非200状态码) """ try: response = requests.get( url, headers={"User-Agent": "Mozilla/5.0"}, timeout=5 ) if response.status_code != 200: return response.text return f"非404页面,当前状态码:{response.status_code}" except requests.exceptions.RequestException as e: return f"请求异常:{str(e)}" def error_response(exception, code, message, filepath): """构建错误响应模板""" return { "status": code, "error": { "type": exception.__class__.__name__ if exception else "UnknownError", "details": str(exception) if exception else "" }, "message": message, "failed_path": str(filepath) if filepath else None } if __name__ == "__main__": mcp.run(transport='sse') ``` 三、MCP客户端对接 ========== 3.1 对接Cline ----------- 目前常用的mcp客户端有 **Cursor**,**Cherry Studio**,**Cline(插件)**,但只有Cline支持**更改时间延迟**,故以Cline为例 首先进入工具目录,允许以下命令,开启sse服务 ```sh uv run main.py ``` 如图便是开启成功  然后Vscode下载最新版Cline插件,进入远程MCP服务添加页面,名称自定义,URL填写 `http://0.0.0.0:8000/sse`,并保存  在已导入的MCP服务中,将超时时长设置为**10min**(视扫描时长而定),如果保存后无法连接mcp服务器,建议点击 Configure MCP Servers 选项,然后对弹出的配置json 进行ctrl+s 保存 我们在该界面便能看到对tool的介绍  建议在对话中开启MCP自动调用,这样更加方便  3.2 提示词优化 --------- 经测试,使用以下提示词效果更好 ```php 请帮我使用已有的mcp工具扫描网站https://xxx.xxx.top/ ,非200响应页面都要调用get_content函数获取内容,判断是否存在版本目录泄露等漏洞,并输出得到的目录,状态码,危害,利用方法,修复方法,以表格的形式统一给我写在md文件中 ```
发表于 2025-04-29 10:00:00
阅读 ( 9495 )
分类:
AI 人工智能
6 推荐
收藏
2 条评论
Elite
Ctfer
2 篇文章
×
温馨提示
您当前没有「奇安信攻防社区」的账号,注册后可获取更多的使用权限。
×
温馨提示
您当前没有「奇安信攻防社区」的账号,注册后可获取更多的使用权限。
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!